Imagine trying to have a conversation but forgetting everything you’ve ever learned after each sentence. That would be frustrating, right? This is exactly the challenge agents face without a robust memory system. They can perform incredible tasks – from answering complex questions to executing multi-step workflows – but they struggle without a way to retain and access the vast amount of information they need. Like us, even the smartest agents need a strong memory to function effectively.
This is where a vector database like open source Milvus comes in. It provides the essential backbone for these agent systems by offering a powerful solution for storing, managing, and retrieving data. With Milvus, agents don’t have to “forget” after each interaction; instead, they can recall relevant data instantly, improving their efficiency and decision-making.
In this blog post, Stephen Batifol will explore how Milvus plays a critical role in enhancing agent systems. By exploring Milvus's capabilities, he will show how to unlock agents' full potential and take AI interactions to the next level. Let’s get started!
Understanding Agents
Agents are more than just advanced tools; they’re capable of autonomous thought and action, distinguishing them from traditional systems. Their ability to reason, plan, and learn allows them to perform complex tasks go beyond simple input-output responses. Let’s take a closer look at what makes agents unique:
Reason: Agents can process information and understand the context of a situation.
Plan: They can develop strategies to achieve specific goals, breaking down complex tasks into smaller, manageable steps.
Learn: Agents can adapt to new information and improve their performance over time.
Here is a high-level overview of how they typically work:
Perception: The Agent receives input from their environment, such as user queries, sensor data, or database information.
Reasoning: Using a large language model (LLM), the agent processes its input to understand the context of the task or query, interprets the requirements and constraints, and analyzes relevant information from its knowledge base.
Planning: Based on its understanding, the agent formulates a plan of action. This plan includes breaking down complex tasks into smaller, manageable steps, prioritizing actions based on importance or efficiency, and considering alternative approaches and their potential outcomes.
Execution: This is where the agent springs into action, carrying out the planned actions. It might generate text responses or summaries, call external APIs to retrieve or manipulate data, trigger other systems or processes, provide recommendations, or make decisions.
Learning: The agent updates its knowledge based on the outcomes of its actions. After execution, the agent can evaluate the outcomes of its actions, update its knowledge base with new information, and refine its decision-making processes for future tasks.
This continuous cycle of perception, reasoning, planning, execution, and learning is the key to the agent's ability to perform increasingly complex tasks with greater efficiency over time. The agent's constant learning and adaptation mean that it is always evolving, becoming more effective as it gathers experience and information.
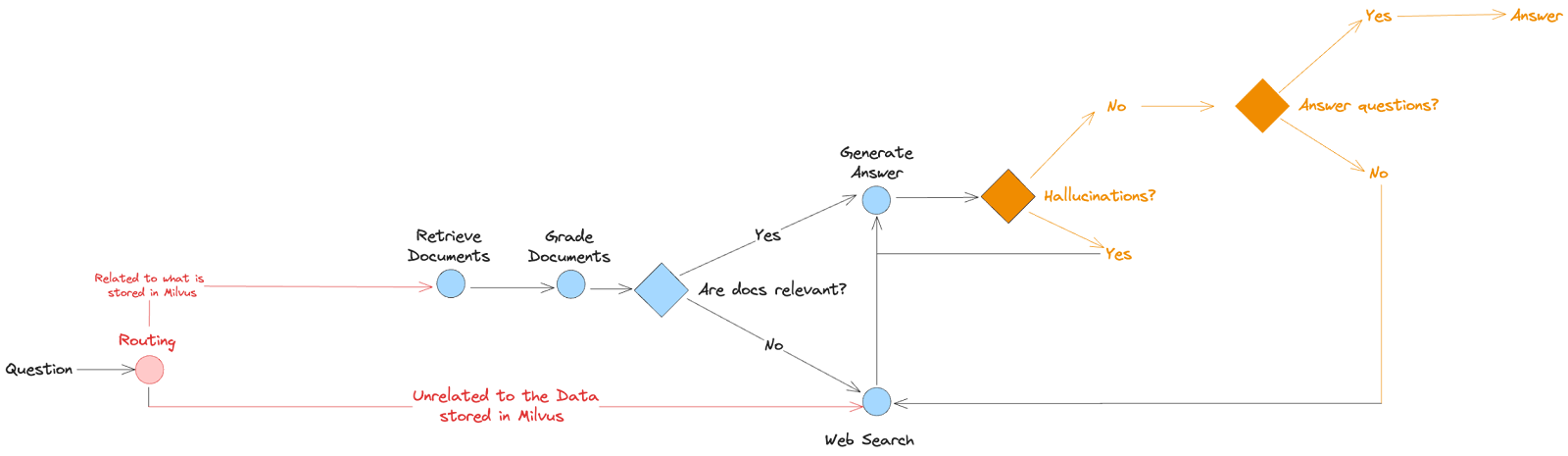
Example of a self-correcting agent
In the next section, we’ll explore how the Milvus vector database integrates with these intelligent agents to enhance their capabilities and ensure their peak performance.
Milvus: The Backbone of Agent Memory
While agents are often celebrated for their ability to understand and respond to complex prompts, their true potential lies in their ability to learn and adapt. To do this effectively, they need a robust memory system capable of storing, organizing, and retrieving vast amounts of information. This is where Milvus truly shines.
Milvus is a popular open-source vector database, created by the team at Zilliz, that powers AI applications with highly performant and scalable vector similarity search. Let's take a look at how Milvus meets agents' memory needs.
A. Long Term Memory
Milvus stores and retrieves semantic information, which is crucial for agents' long-term memory. Here's how it works:
Efficient Indexing: Milvus uses advanced indexing techniques like HNSW to organize vector embeddings. This capability allows for quick navigation through the high-dimensional space.
Flexible Schema: Milvus supports dynamic schema, allowing you to store additional metadata alongside your vectors. This is particularly useful for storing context or source information related to each vector embedding.
B. Efficient Retrieval for Context Management
Milvus's architecture is optimized for fast, relevant information retrieval, which is critical for agents to maintain context during interactions. Here's how Milvus enables this functionality:
Approximate Nearest Neighbor (ANN) Search: Milvus uses ANN algorithms to quickly find the most similar vectors to a query. This refers to finding the most relevant information for the agent's current context.
Hybrid Search Capabilities: Milvus supports combining vector similarity search with scalar filtering. This allows different agents to consider semantic similarity and specific attributes when retrieving information.
Real-time Search: Milvus's architecture supports real-time data insertion and near real-time search, ensuring that agents can always access the most up-to-date information.
C. Scalability and Performance
As agents grow in complexity and handle increasing amounts of data, scalability becomes crucial. Milvus shines in its ability to handle large-scale data:
Distributed Architecture: Milvus is designed with a distributed architecture, allowing it to scale horizontally across multiple nodes. This means allowing agents to handle massive amounts of information without sacrificing performance.
Load Balancing: Milvus automatically distributes data and query load across the cluster, ensuring optimal resource utilization.
Sharding: Large datasets are automatically sharded across the cluster, allowing for parallel processing of queries.
Milvus's high-performance capabilities are evident in its:
Low Latency: Milvus can return results in milliseconds, even with billions of vectors.
High Throughput: Milvus can handle thousands of queries per second (QPS), making it suitable for high-traffic applications.
By providing a reliable and scalable memory system, Milvus empowers agents to learn, adapt, and perform at their best.
Conclusion
The future of AI is truly exciting, and the capabilities of agents are expanding at an incredible pace. As these agents move beyond simple text-based interactions to incorporate multiple forms of data, the need for a strong, scalable memory system becomes even more essential.
Milvus is at the forefront of this shift, leading the way in AI-powered interactions. By offering efficient storage, rapid vector retrieval, and the ability to scale, Milvus equips agents with the power to:
Store and retrieve massive amounts of data: Whether it's text, images, audio, or video, Milvus handles it all with ease.
Make smarter decisions: With quick access to relevant information, agents can make more informed, context-aware choices.
Learn and adapt: By efficiently storing and retrieving data, agents can learn from past interactions and improve over time.
As agents continue to evolve, vector databases like Milvus will be crucial in shaping their capabilities. By providing a robust memory system, Milvus enables agents to become more versatile, understanding, and capable of handling complex tasks.
This journey is just beginning, with vast potential for innovation ahead. Whether you're a developer, researcher, or AI enthusiast, exploring tools like Milvus can unlock new possibilities and help you stay on the cutting edge of AI technology.
We'd love to hear what you think!
If you like this blog post, we’d really appreciate it if you gave us a star on GitHub! You’re also welcome to join our Milvus community on Discord to share your experiences. If you're interested in learning more, check out our Bootcamp repository on GitHub for examples of how to use Agents with Milvus. We'd love to hear what you think!
*This post was written by Stephen Batifol and originally published on Zilliz.com here. We thank Zilliz for their insights and ongoing support of Turing Post.
