- Turing Post
- Posts
- Revolutionizing Time Series Forecasting: Interview with TimeGPT's creators
Revolutionizing Time Series Forecasting: Interview with TimeGPT's creators
It's not an LLM! Azul Garza and Max Mergenthaler talk innovations, open-source, diversity, and pain of wrangling 100 billion data points
Ksenia Se & Ian Spektor
April 05, 2024

If you like Turing Post, please consider to support us today
Today, we're excited to welcome Azul Garza and Max Mergenthaler, co-founders of Nixtla and researchers behind TimeGPT, the first foundation model designed specifically for time series forecasting (→read the paper here). Time series are used to analyze trends, identify seasonality, forecast future values, and detect unusual patterns, and more. Foundation models are revolutionizing time series forecasting because they are pre-trained on vast amounts of diverse data, enabling them to adapt to new forecasting tasks efficiently. This translates to versatile models that can handle complex data patterns, eliminating the need for custom models for each specific use case. Just recently, giants like Amazon (Chronos), Google (TimesFM), and Salesforce (Moirai) have released their proprietary time series foundation models. More breakthroughs are awaited in 2024!
Great to have you for this interview, Azul and Max. How did you come up with the idea for TimeGPT?
We have been working in the time series space for quite a while, and when we started Nixtla 3 years ago, we started it with the goal to help all practitioners with best-in-class implementations of classical and contemporary algorithms. We began developing various open-source libraries that have now become the Nixtlaverse. This is the most comprehensive open-source time series project to date, including statistical, machine learning and deep learning models, and we’ve been excited to see that they’re being used by many Fortune 100 companies and startups alike, and have been downloaded more than 10 million times. As developers and maintainers of these libraries, we've had the privilege of working with top data science teams across the globe, and realized that a main obstacle in forecasting is that it remains an extremely hard and expensive process that requires a highly skilled team. We wanted to change that and democratize access to state-of-the-art time series tools, without the need for a dedicated team of machine learning engineers. Inspired by the revolution of OpenAI and others in text processing, we aimed to bring the whole paradigm shift of generative pre-trained models to time series. It wasn’t clear yet if there could be an effective foundation model in time series analysis, so we set out to explore what was possible and how accurate it could be. We didn’t want to do this just for the sake of it being done. We wanted it to provide fast and accurate results for people working in time series. This is how TimeGPT, the first foundation model for time series, was created and released.
How exactly does TimeGPT differ from an LLM? How is time series data transformed into tokens to be fed to the transformer?
We get this question a lot: GPT here stands for a generative pre-trained transformer, which is in no way related to a classical Large Language Model (LLM). The GPT in ChatGPT stands for the same thing, because they use transformer approaches, but we don’t do the Language part, we do the data part and deal with time series data. We essentially built a completely new model that was trained using publicly available time series from different domains, including retail, IoT, manufacturing, healthcare, electricity, and web traffic. It does not understand text; it only understands time series for forecasting and anomaly detection tasks. Technically speaking, the optimization function of TimeGPT is very different from the sequence prediction task in natural language contexts. In our case, the model takes as input the data with timestamps, values, and exogenous variables and outputs predictions or the anomalies detected. That means, when we speak about tokens in TimeGPT, we are really referring to timestamps. There is no embedding process in our case.
Despite deep learning's transformative impact on fields like NLP and computer vision, its contributions to time series forecasting have been more measured. From your perspective, what breakthroughs does TimeGPT represent in this context?
That’s a great question. There was a lot of discussion in the field as to whether deep learning approaches would outperform classical models. We did a lot of comparisons and work in this space ourselves, and the classical models do very well in many contexts! Readers familiar with our past contributions will remember that Nixtla has played a pivotal role in demonstrating how classical models outperformed many so-called state-of-the-art models with a fraction of the cost and complexity. We have published different experiments showcasing this. Therefore this evaluation of deep learning models is at the leading edge of the field, and we’ve done research in this space for many years. TimeGPT has been the first demonstration that a deep learning approach can not only outperform existing approaches, but also is much, much faster. From our perspective, the breakthroughs that TimeGPT represents in this context are significant.
We believe that times are changing, mainly due to data and compute availability. Currently, deploying pipelines for time series forecasting involves several steps, from data cleaning to model selection, that require a lot of effort and specialized knowledge unavailable to many users and companies. Pre-trained models offer a whole new paradigm in time series forecasting and anomaly detection given that users don’t have to train and deploy their own models. Simply upload and forecast.
The main breakthrough of TimeGPT is that it showed for the first time in the history of the field that the idea of a general pre-trained model was possible. In other words, TimeGPT is the first large-scale example of the transferability of time series models ready for production. We believe this marks a new chapter in the time series field, and we are extremely happy to see entities like Google (TimesFM), ServiceNow (LagLlama), Amazon (Chronos), Salesforce (Moirai), and CMU (Moment) following in our footsteps and contributing to this idea of pre-trained models for time series.
I'm curious about the choice of a Transformer-based model for TimeGPT. What drove this decision, and how has it influenced the model's performance and its ability to scale?
The short answer is: it was empirical. We tried (and are still trying) different deep learning architectures for time series. In our tests, we found transformers to be highly scalable and accurate when using huge and diverse amounts of data.
Dealing with uncertainty is key in forecasting. As well as understanding underlying temporal dynamics, such as seasonality and trends. How does TimeGPT tackle this, and does it have any edge over more traditional methods?
We could spend hours writing about explainability and uncertainty quantification in time series, and we believe those are extremely exciting topics in the field. They’re some of our favorite things to discuss! In the case of TimeGPT, we currently support uncertainty quantification with Conformal Prediction and will soon release other forms of probabilistic forecasting with multi-quantile and distribution losses. Additionally, TimeGPT offers the possibility of understanding the different weights that exogenous variables play in your forecasts. For example, with our weights function, you can see if certain holidays or aspects such as weather are driving your sales up or down. Understanding the role of different covariates in the output creates the possibility to build what-if scenarios easily, and in just a few lines of code.
How does TimeGPT stack up against other state-of-the-art deep learning models tailored for time series forecasting, such as DeepAR, PatchTST, or TFT, especially in terms of computational efficiency and prediction accuracy?
We conducted a large benchmark with more than 300,000 unique series, comparing zero-shot accuracy of TimeGPT (namely, the model never saw this data during training) against classical, machine learning, and deep learning models that were trained on the data. We found that TimeGPT, even without training, outperformed all other methods for weekly and monthly data and scored second and third for daily and hourly data. In terms of speed, TimeGPT is orders of magnitude faster than other deep learning models.
For zero-shot inference, our internal tests recorded an average GPU inference speed of 0.6 milliseconds per series for TimeGPT, which nearly mirrors the simple Seasonal Naive. As points of comparison, parallel computing-optimized statistical methods, when complemented with Numba compiling, averaged a speed of 600 milliseconds per series for training and inference. On the other hand, global models such as LGBM, LSTM, and NHITS demonstrated an average of 57 milliseconds per series, considering both training and inference. Due to its zero-shot capabilities, TimeGPT outperforms traditional statistical methods and global models in total speed by orders of magnitude.
This is extremely important because it opens the possibility of new low-latency use cases in IoT, Web Monitoring and Manufacturing.
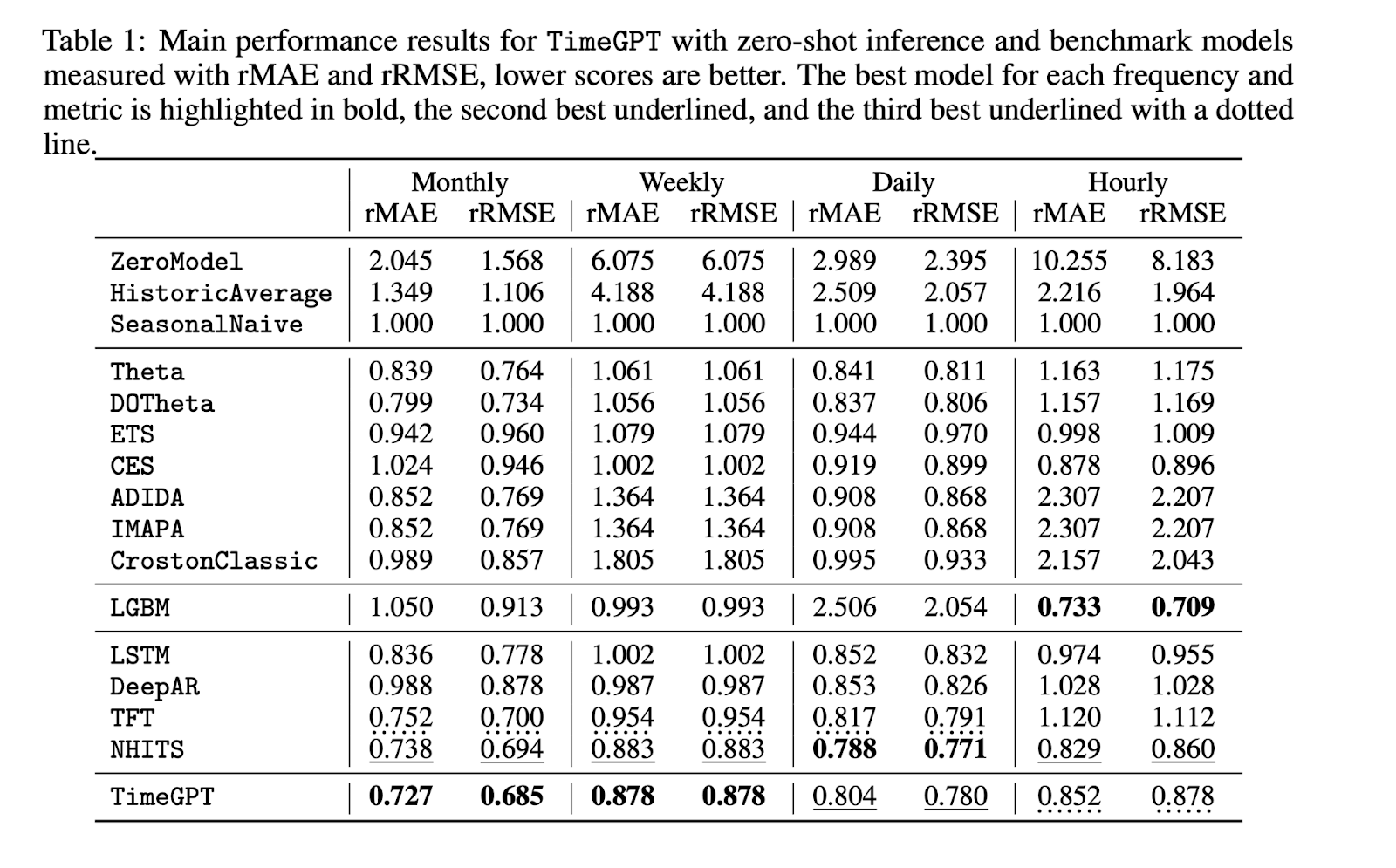
What key differences exist between TimeGPT and other recent open-source time series foundation models such as LagLlama, PreDcT, TimesFM, and MOIRAI? Are you planning to benchmark TimeGPT against the open-source ones?
We are seeing two families of foundation models emerge in the field: one family, like LagLlama and Chronos, leverages actual LLM models or intuitions behind their architectural design, and others, like TimeGPT and Moirai, rely solely on time series data and architectures. So far, we have found TimeGPT significantly faster and more accurate than its competitors, but we are currently working on a large-scale benchmarking of all available foundation models before we make any official conclusions.
Meanwhile, we have released open and fully reproducible benchmarks of Moirai, Chronos, and LagLlama. We found that LagLlama is 40% less accurate than a simple Seasonal Naive and 1000x slower. We also found that Amazon Chronos is 10% less accurate and 500% slower than training classical statistical models. Those results were validated by Amazon in the selected datasets (however, Amazon expanded our benchmark with new datasets and showed that Chronos could be 4% more accurate and faster than statistical models). We also found that Salesforce's Moirai performs great in hourly data and is much faster than Chronos but is still up to 33% less accurate and less efficient than statistical models when considering monthly, weekly, and yearly data.
Conducting benchmarks against different models, in an open and reproducible way, is important to us as a company. We share our experiments and code in our GitHub repository: https://github.com/Nixtla/nixtla/tree/main/experiments
TimeGPT was trained on a proprietary dataset of over 100 billion data points (orders of magnitude larger than the largest available public datasets). What does it entail to put together such a dataset? Any plans to open-source it?
Pain, sweat, and tears. And lots of data wrangling. Jokes aside, creating that dataset was an important effort that gave us a significant advantage against titans such as Amazon, Google, and Salesforce. We were able to do this because of our team’s extensive experience in not just time series research, but also in being users, and working with so many people using our open source tools. We had a good understanding of what data was important, and the depth and variability needed. We are indeed considering open-sourcing the data and maybe even some earlier versions of the models, but can't promise anything. That being said, all our libraries are completely open source and always will be open source, and can be used to train more foundation models.
Training the model in a broad range of scenarios allows the model to learn patterns that repeat between series, that it wouldn't be able to predict if trained on a single series. As an example, it could predict a new pandemic from other pandemics' data. Have you done any tests or have any insights into this line of work?
Training in a source domain and then forecasting in a new target domain encapsulates the whole idea behind the transferability of time series models. We are working on a paper that precisely explores that. Generally speaking, transfer learning is a machine learning technique that involves applying knowledge acquired from solving a source task to enhance performance on a distinct yet related task. Models pre-trained on large datasets for the source task learn valuable patterns and representations, which can help smaller target tasks by improving the models’ generalization and reducing their computational costs and data requirements. Our empirical findings confirm that this is indeed the case for time series, and pre-trained models can outperform the accuracy of widely adopted automatic forecasting tools, with computational speed improvements on the orders of magnitude. In our exploration of what makes transferability work, we discovered that the source dataset’s size and diversity play a critical role in the accuracy of pre-trained models. So, we’ve seen some evidence already that this is possible, and are optimistic for good performance on the types of applications like pandemic predictions.
What's next on the horizon for TimeGPT? Are there any areas you're particularly keen to enhance or expand into?
Nixtla has a clear vision of becoming the go-to solution for time series practitioners. We have invested a lot of time and effort in making state-of-the-art open source tools available to practitioners and have also invested significant time in making TimeGPT usable for everyone through fully or self-hosted versions of the models. That means that now individuals, or organizations of all sizes can perform out-of-the-box forecasting tasks or replace thousands of lines of code with a few API calls.
We have a very ambitious roadmap for the future and are constantly working on new features and better models. Multimodality in time series is the next big thing, and something we’re working on.
As we look to the future, what 'big questions' in AI do you think need more attention? Or, are there any emerging fields that catch your eye?
There do remain so many big questions with broad societal and economic impacts. We believe the field would benefit from more diversity. We are extremely proud to be a queer and Latino-founded company and believe that having more diverse backgrounds in the space would benefit everyone. Our thesis is: that diversity of data improves forecasting accuracy, but it also makes a better ecosystem.
What book would you recommend to aspiring data scientists/ML engineers? (It doesn’t necessarily have to be about ML!)
We like Rob Hyndman and George Athanasopoulos’s book, Forecasting: Principles and Practice, because it combines the theory with examples and code for practical implementation. We’re also very excited that we get to work on the Python version of this book, so that’s coming soon.
We have some recommendations when talking with aspiring engineers, and something we always keep in mind ourselves. Learn the basics. Always benchmark. Simpler is many times better. Prophet is a bad forecasting algorithm.
Happy Forecasting!
Thank you for reading! if you find it interesting, please do share 🤍
This interview would not be possible without the help of Ian Spektor, Lead ML Engineer at Tryolabs, an AI consulting company that helps companies accelerate their AI adoption.
Reply