
We have already discussed the Mixture-of-Experts (MoE) architecture in our first AI 101 episode (it provides a history of MoE as well). This approach reshaped how we build and understand scalable AI systems. It uses only a part of experts and parameters for specific tasks to enhance effectiveness of models and make their cost lower. But here’s one problem – most of the MoE models are close-source. A new OLMoE model aims to close the gap between frontier models and fully open models, proposing more efficient algorithms and smaller number of parameters compared to MoE to reduce cost of this type of models.
As of today’s news (Sept 25), according to Niklas Muennighoff: “OLMoE is now multimodal (MolmoE) as part of the Molmo family". We will explore Molmo in the next installments, today we want to focus on OLMoE, its idea and features and how it benefits the community.
In the spirit of OLMoE’s fully open-sourced model – we’ve made this AI 101 episode freely accessible as well. If you want to contribute to the future of AI education and support more content like this, upgrade your Turing Post subscription →
In today’s episode, we will cover:
What’s the idea behind OLMoE?
How does OLMoE work?
How many experts and parameters are used in OLMoE?
But how did researchers come up with these numbers?
How good is OLMoE-1B-7B?
Advantages of OLMoE
Limitations
Conclusion
Bonus: Resources
What’s the idea behind OLMoE?
The best models are often too computationally expensive to train and deploy, often putting them out of reach for smaller organizations and researchers. Mixture-of-Expert (MoE) architecture of models traditionally solves the problem of high cost of dense AI systems. MoEs use several experts per layer but activate only a few at a time, making them more efficient. Top models including Mistral, Databricks' DBRX, AI21 Labs' Jamba, xAI's Grok-1 utilize MoEs. It is also widely believed that GPT-4 utilizes a MoE architecture.
However, most MoE models aren't open to the public, so this limits the community's ability to create competitive, cost-effective MoEs.
To solve this, researchers from Allen Institute for AI, Contextual AI, University of Washington and Princeton University created OLMoE, an open-source MoE model with great performance. They have made the model weights, code, logs, and data they used to train it all open-source. So anyone can see how it works, use it, or even improve it. This also makes the working process of OLMoE more transparent. So →
How does OLMoE work?
Instead of using one large set of operations like dense models, OLMoE being a MoE model uses multiple smaller operations called "experts." One of the most important feature of OLMoE is that its experts are highly specialized. For example, one expert might specialize in language translation while another might focus on mathematical reasoning.
Out of a group of experts, only a few are activated each time a word or input is processed, which makes the model more efficient.
A part of the model called the "router" decides which experts to use for each task based on the input. The router calculates probabilities and chooses the best experts, whose outputs are combined to generate the final result.

How many experts and parameters are used in OLMoE?
In MoE models, key decisions include how many experts to use, how they are designed, and how the router selects them.
The number of active parameters in OLMoE was chosen to balance efficiency and performance. OLMoE has 6.9 billion total parameters, but only 1.3 billion are used at a time for each input. This is done by activating 8 out of 64 experts for each task.
But how did researchers come up with these numbers?
To determine these specific numbers, researchers conducted extensive experiments. They found that activating fewer than 8 experts per input reduced the model’s accuracy, while activating more experts unnecessarily increased computational costs. The final choice of activating 8 experts was made because it struck the best balance between accuracy and computational efficiency. The technique used for selecting which experts to activate is called token-based routing, where a learned router assigns each input token to its most relevant experts without dropping any tokens, maximizing the model's effectiveness.
The model's efficiency was further boosted through the dropless token choice routing method, which avoided overloading a single expert and ensured that each input is processed by specialized experts without any loss of information. This combination made OLMoE about twice as fast to train as traditional dense models of comparable size, all while maintaining similar inference costs to models with far fewer total parameters.
Researchers pretrained OLMoE on a large dataset of 5 trillion tokens, which gave the experts enough exposure to different kinds of data to specialize deeply. This specialization resulted in better performance without needing to increase the number of active parameters.
They also employed several techniques to ensure model stability and efficiency throughout training. Load-balancing loss was used to make sure that all experts were used evenly, avoiding situations where certain experts were overused while others were underutilized. Additionally, router z-loss was applied to prevent large logits (model decisions) from causing instabilities, improving both performance and training consistency.
These carefully selected methods allowed the researchers to achieve optimal results with 6.9 billion total and 1.3 billion active parameters, making OLMoE a highly efficient and powerful model without unnecessary computational overhead. Let’s see some graphs.
How good is OLMoE-1B-7B?
Developers evaluate the performance of OLMoE during three stages: during pretraining, after training and after adapting the model.
During pretraining:
OLMoE-1B-7B consistently outperforms other models, including dense models like OLMo-7B, across all tasks.
Despite using only 1.3 billion active parameters, it requires less computational power (FLOPs) than its competitors.
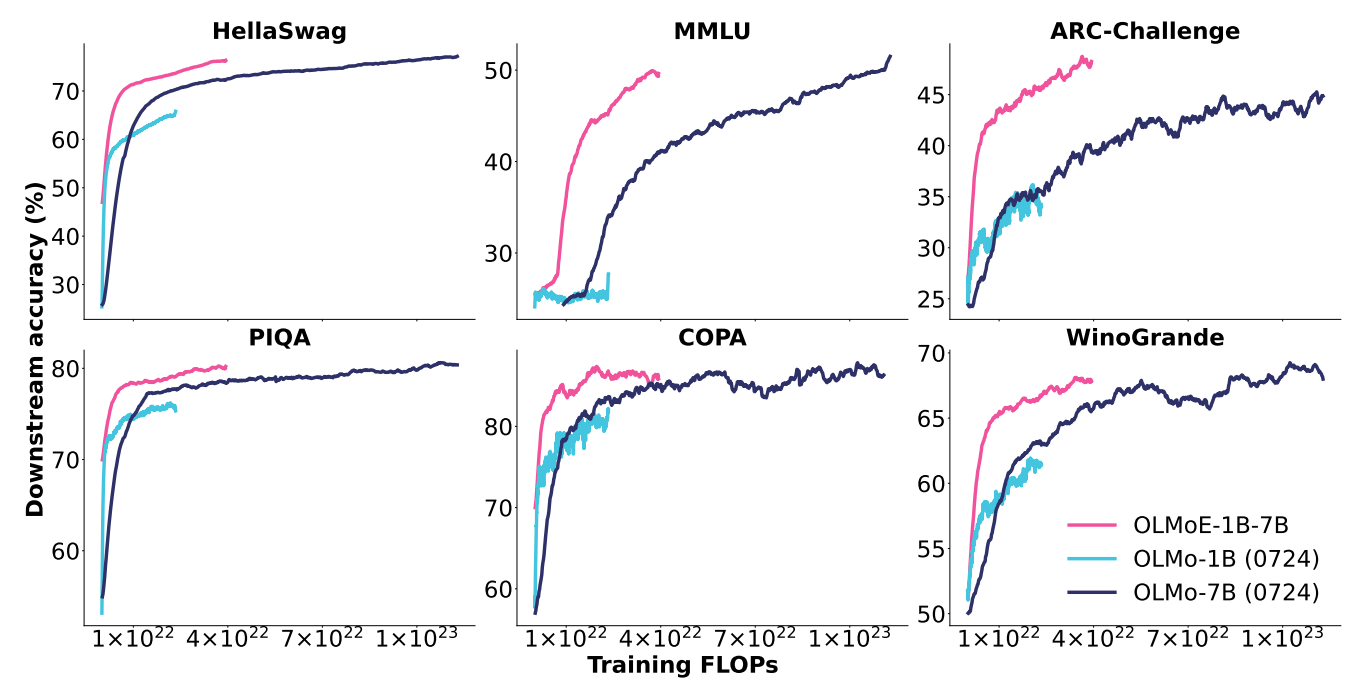
Image credit: Original OLMoE paper
After pretraining:
OLMoE-1B-7B outperforms other models with fewer than 2 billion parameters.
For models with larger computational budgets, Qwen1.5-3B-14B achieves better performance, but it has over twice the number of parameters compared to OLMoE-1B-7B.
OLMoE falls short when compared to models like Llama3.1-8B, which have even more parameters and compute capacity.
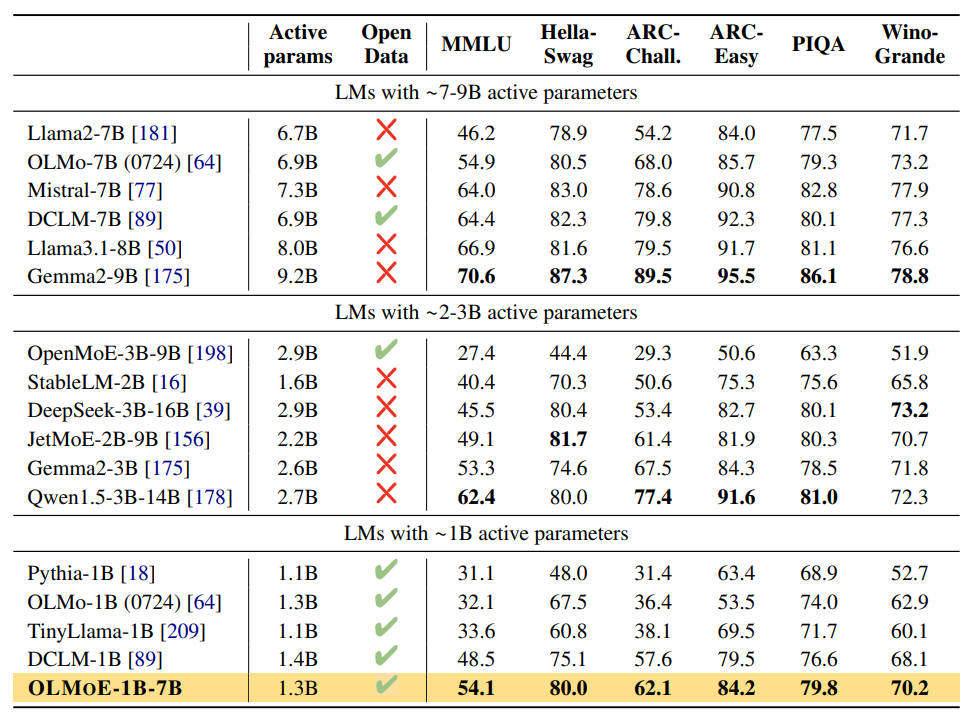
Image credit: Original OLMoE paper
After adaptation:
Adaptation includes fine-tuning the model for specific tasks (like coding and math). For this, a two-step process is used:
SFT (Supervised Fine-Tuning): Tuning the model for specific instructions.
DPO (Direct Preference Optimization): Tuning the model to align with user.
Researchers added more data related to code and math to help the model improve in these areas, similar to other models, like GPT-4.
Results:
SFT increases performance especially on tasks like GSM8k.
DPO tuning further enhances performance, especially on the AlpacaEval.
The tuned version, OLMOE-1B-7B-INSTRUCT, performs better in some areas than much larger models like Qwen1.5-3B-14B, despite having fewer parameters.

Image credit: Original OLMoE paper
Advantages of OLMoE
For now, we exactly need to make a summary of advantages of OLMoE to clarify why it is a better version of MoE architecture:
Open-source: OLMoE is fully open-source, giving access to its working process for all users and developers.
Efficiency and cost-effectiveness: Activating only a few specialized experts at a time reduces computational power usage, lowering costs and increasing efficiency compared to dense models. With 64 experts and only 8 active, OLMoE enhances performance without extra costs and requires fewer active parameters than standard MoE.
Performance: OLMoE is highly competitive with even larger models without increasing cost. Standard MoE may achieve similar or higher levels of performance, but often at the cost of requiring more compute resources.
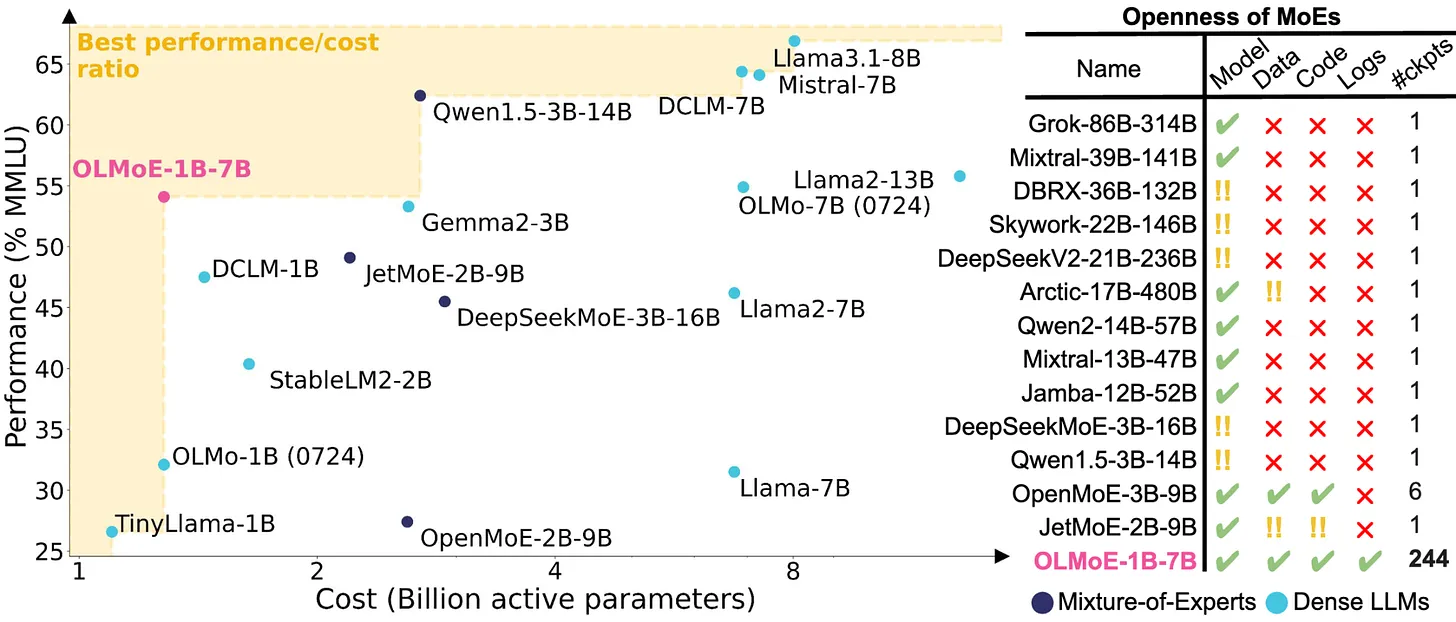
Image credit: Nathan Lambert blog
Limitations of OLMoE
OLMoE also have several limitations, mostly because of more complex architecture than dense models:
Routing complexity: Inefficient or suboptimal expert routing can add overhead and lead to less effective expert activation and lower model performance for specific inputs.
Memory requirements: OLMoE, with 6.9 billion total parameters, requires substantial memory resources, particularly for GPU processing.
Scalability challenges: While current configuration is effective, larger models may face complicated management and routing because of more experts.
Data dependency: OLMoE needs a large, diverse, and well-balanced dataset for effective training. Poor data curation or underrepresented domains can lead to worse performance.
Conclusion
Based on the MoE but being a more advanced model, OLMoE is an efficient and powerful system that makes the Mixture-of-Experts architecture, with all its advantages, accessible to everyone. Open-source models are breaking through with performance on par with or even better than closed models, and OLMoE is one of them. It demonstrates how the idea of making MoE technology transparent leads to an overall upgrade of the system. Once again, the Allen Institute for AI, whose researchers led the project, demonstrated an amazing dedication to advancing the ML community and democratizing model development.
Quoting Nathan Lambert: “This will help policy. This can be a starting point as academic h100 clusters come on line. Open-source language modeling is in its early days.”
Bonus: Resources
OLMoE and the hidden simplicity in training better foundation models by Interconnects
