
You may have noticed that transformers don’t regulate the computing power allocated to each token or word in a sequence. However, some words require more attention, while others can be bypassed as they contribute less (just as in real life). To achieve efficient computational use, researchers from Google DeepMind, McGill University, and Mila have proposed a new method – Mixture-of-Depths (MoD). This approach optimizes how transformers use computing power (FLOPs) by identifying which parts of an input sequence need more focus. Let’s dive deeper into the “depths” of transformers, exploring how MoD works, its impact on overall performance, and how it might benefit you.
In today’s episode, we will cover:
Too much computation needs in Transformers
Here comes Mixture-of-Depths (MoD)
How does MoD work?
More about routing
What’s about MoD performance?
Benefits of MoD
Challenges with MoD
Solutions to challenges
Implementation: Mixture-of-Depths-and-Experts (MoDE)
Conclusion
Bonus: Resources
Too much computation needs in Transformers
Transformer models usually spend the same amount of computing power on each word, which is not necessary. Transformers could save power if they focus only on words that need extra processing.
Conditional computation is a common approach to manage computing power in transformers, often through techniques like early exiting and Mixture-of-Experts (MoE). Early exiting allows the transformer to stop processing certain tokens once they have received sufficient attention, skipping remaining layers. In MoE transformers, tokens are directed only to the experts they need, with other parts of the model left inactive for those tokens.
Can something be more efficient than the approaches we already have? How can we make transformers focus only on tokens that need more processing?
Here comes Mixture-of-Depths (MoD)
This article is a must-read for anyone tracking cutting-edge advancements in AI, especially for those interested in how MoD solves the issue of ineffective use of compute power. Save your time →
To solve these issues Google DeepMind, McGill University and Mila looked deeper in the depth of the transformer architecture and found a more efficient method, which they called Mixture-of-Depths (MoD).
It is similar to the MoE concept with elements of early exiting. The MoD model decides not only if each word (or token) should be processed but also how deeply it should go into the model, as it moves through the network layers. This allows skipping unnecessary layers, saving time and computing power without losing performance.
How does MoD work?
Compute budgeting: Firstly, researchers set a fixed compute limit, called "compute budget," which won’t change mid-process. For example, MoD transformers can set a capacity to only half of the tokens in each layer, and the MoD model learns how to smartly use this compute limit across tokens.
Routing: In traditional transformers, every token goes through all the layers (or blocks) for processing, using a combination of self-attention and MLPs (multi-layer perceptrons). In MoD transformers, however, a "router" evaluates each token, assigning a weight to it, and decides whether each token will:
Go through the full computation (self-attention and MLP). It’s a heavy way.
Take a shortcut via a simpler route called a "residual connection," which skips the heavy computations, saving computing power. It’s a light way.
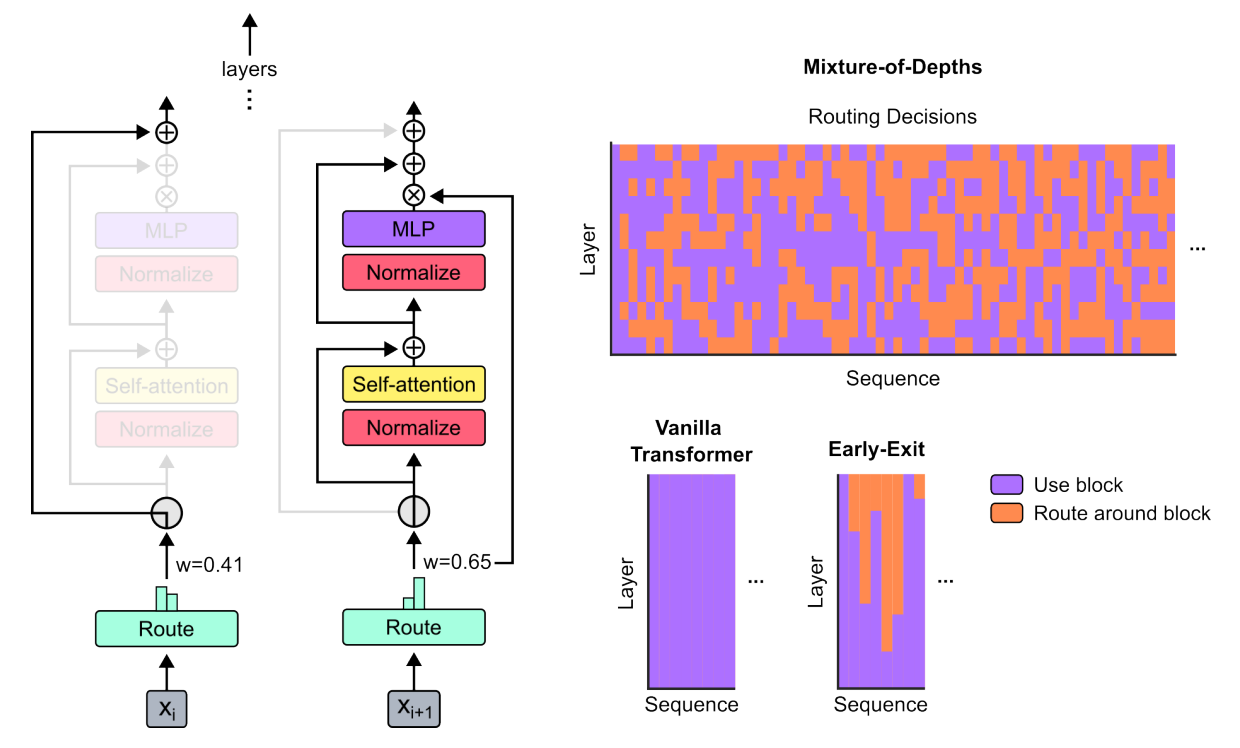
Image Credit: Original paper
More about routing
In MoD, researchers propose using expert-choice routing within a single main computation path, balancing efficiency and performance. Here’s how it works:
For each block, the MoD transformer selects a fixed number (top-k) of tokens to undergo full computation, based on weights assigned by the router. By processing only the most essential tokens, MoD saves computational power.
If fewer tokens require full computation than the total number in the sequence, the rest are "dropped" or lightly processed, conserving resources.
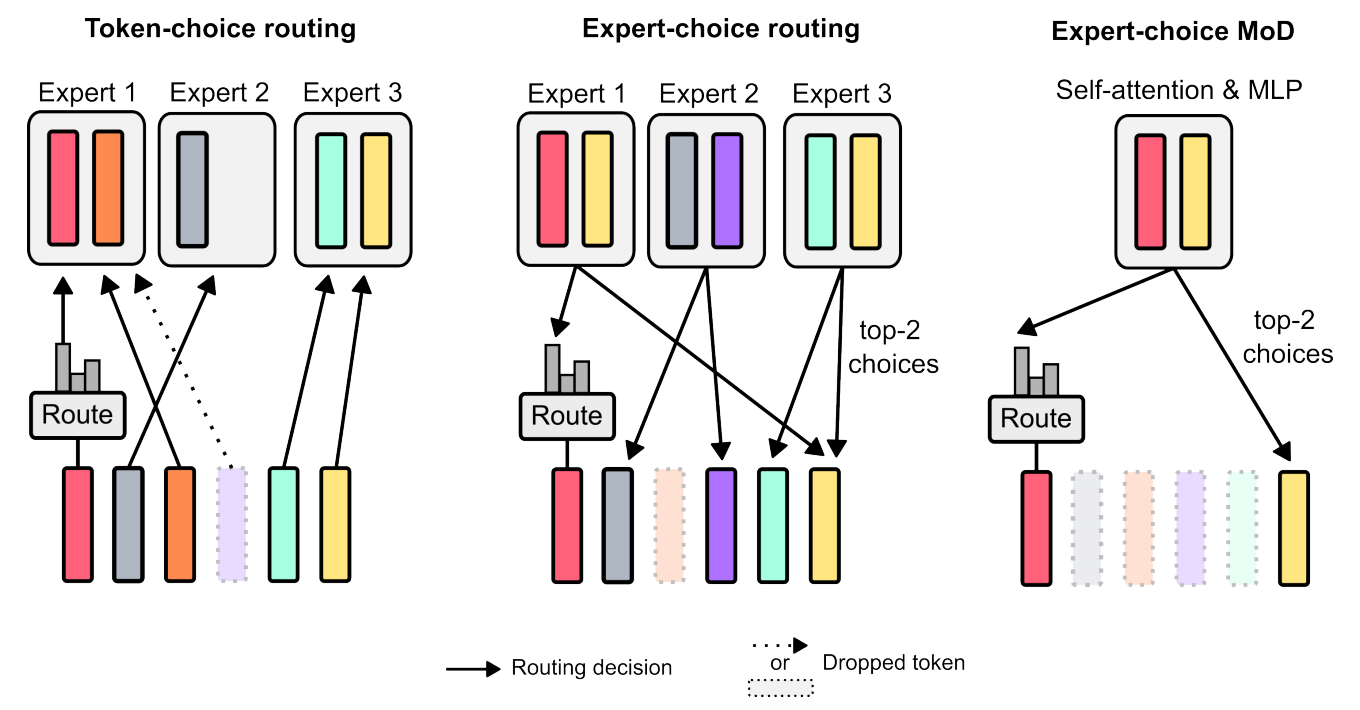
Image Credit: Original paper
This single-path setup allows MoD to reduce processing load (measured in FLOPs) by only sending high-priority tokens through full computational steps. MoD thus maintains a consistent compute load, but dynamically selects which tokens receive deeper processing at each layer. This doesn’t alter the transformer’s structure—just the choice of tokens moving through the layers.
By limiting the number of tokens taking the heavy-compute path, MoD balances computational demand with model effectiveness. For example, if only half the tokens use this intensive route, self-attention computations could require up to 75% less power.
The core idea is balance: if all tokens took the compute-heavy path, MoD would act like a standard transformer; if all took the lightweight path, it would be faster but less precise. The balance between these options makes MoD transformers both effective and efficient.
Another important detail is that unlike the MoE approach, which often applies selective processing of tokens only to specific parts, MoD applies it to both the forward layers (which do calculations) and the attention mechanism (which decides how words relate to each other in the context). So MoD decides not only which tokens get updated but also which tokens should be “seen” by other tokens in the model, helping it focus only on the essential parts of the input.
What’s about MoD performance?
To find the best configuration, MoD models were trained with various fixed computational budgets measured in FLOPs. And also the main question is: Can the MoD model outperform standard transformers?
Experiments showed that MoD transformers are capable of reducing FLOPs per parameter and using fewer parameters for equivalent performance with top models.
Here are the trends in MoD performance that researchers found:
MoD models reached the same performance as the best baseline model but did so up to 66% faster. This speed increase comes from the reduced number of FLOPs needed for each step.
MoD transformers can achieve lower loss (better accuracy) with the same or even fewer FLOPs than baseline transformers.
Some smaller MoD models perform as well as, or better than, baseline models, while using fewer parameters, which makes them faster per step.
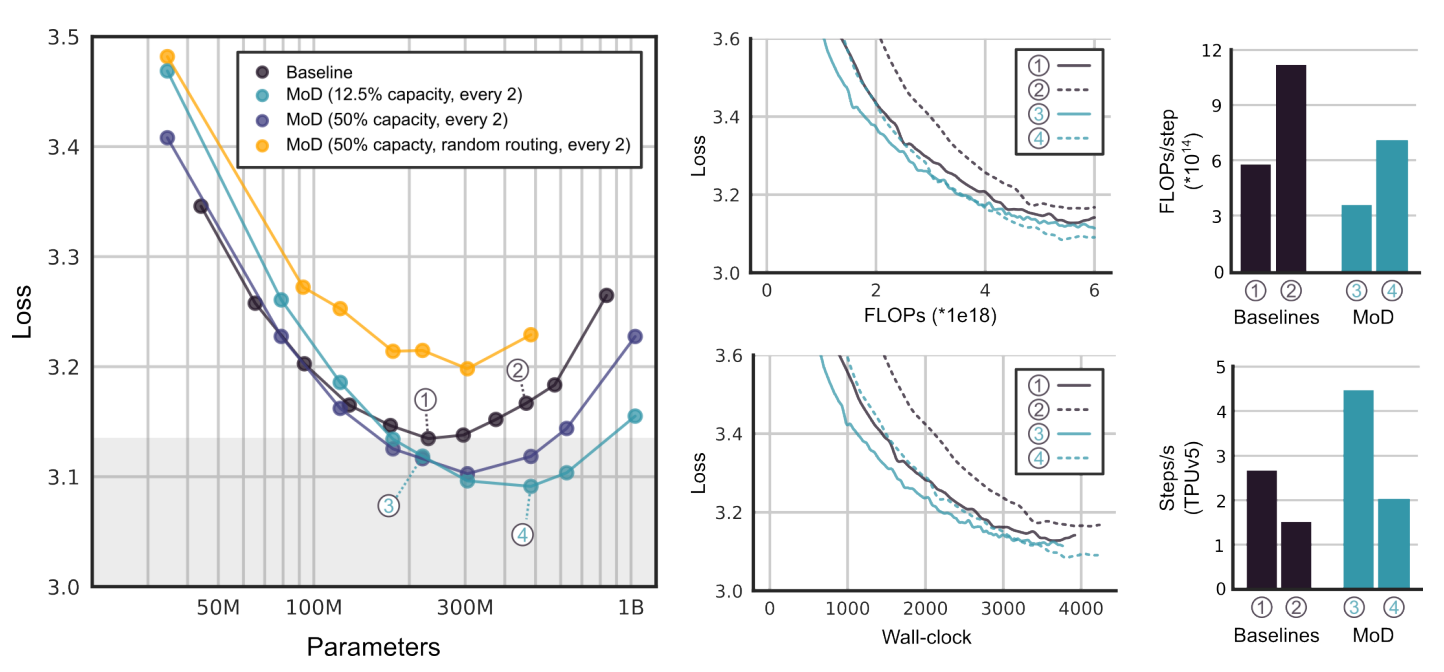
MoD parameter tuning. Image Credit: Original paper
Researchers also found the best setup for MoD transformer which made the model faster and resource-efficient, performing better without using extra computational power. It’s configured with:
12.5% block capacity. This means that only 12.5% of tokens receive full computation per block, while the remaining 87.5% take a faster light route.
Routing every other block instead of every block.
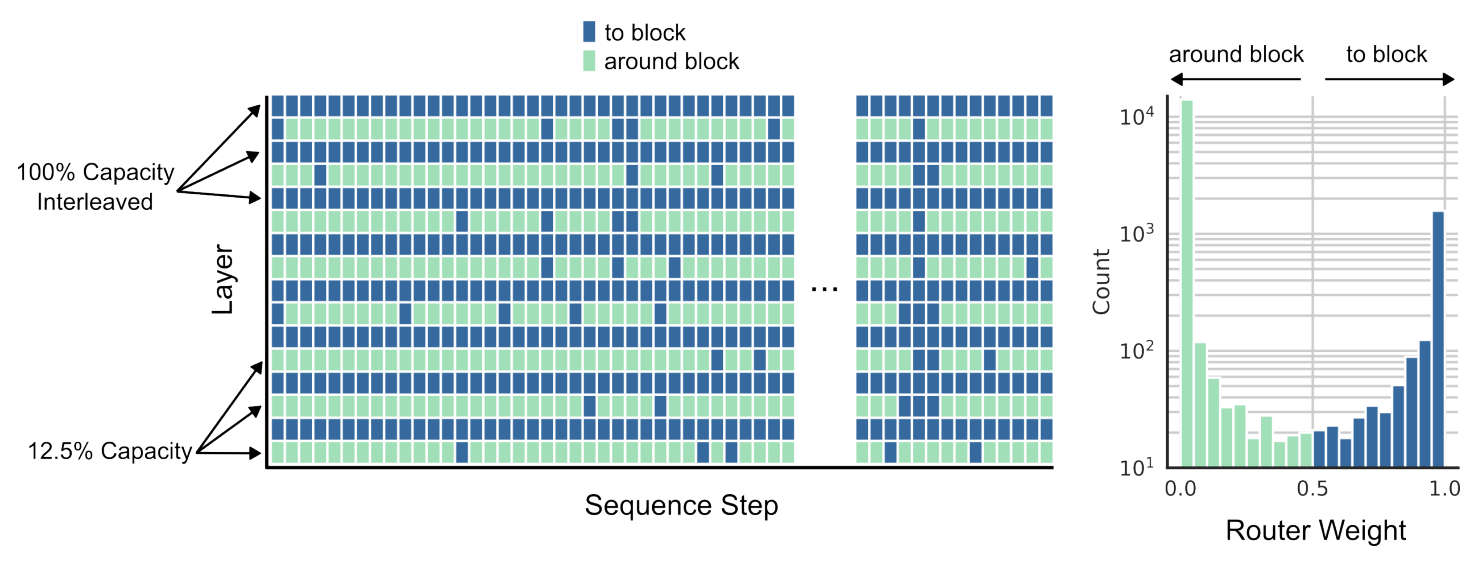
Routing Analysis. Image Credit: Original paper
Now, let’s summarize all the important advantages of the MoD approach, adding some interesting points.
Benefits of MoD
Less computation required and more efficiency: As some tokens take the shortcut and expert-choice routing allows transformers to focus only on essential tokens, MoD transformers save computational power.
Higher speed: Speed increase comes from the reduced number of FLOPs needed for each step. Optimized setup also allows the MoD model to match baseline performance while processing data much faster.
Accuracy: MoD transformers can have more parameters than baseline models but still achieve lower loss.
Another important detail is that MoD transformers can be fine-tuned for either performance or speed:
If focused on performance, MoD transformers can get slightly better prediction accuracy compared to standard transformers. A high-performing MoD model improves accuracy by up to 1.5% compared to standard transformers, using the same amount of computing resources, FLOPs.
If focused on speed, MoD transformers can process data up to 50% faster per step by using fewer FLOPs while maintaining similar prediction accuracy.
Challenges with MoD
While MoD models are promising, they still have several issues:
High training costs: Training MoD models is expensive because the entire model, along with the routers, needs to be trained.
Risk of skipping important layers: Sometimes, crucial layers might be skipped, potentially reducing model performance.
Hardware compatibility issues: MoD models with their dynamic computation requirements may not fully align with current hardware, which often performs best with static computation graphs and fixed memory requirements.
However, some methods which can help overcome these issues already exist.
Solutions to challenges with MoD
To address the challenges of MoD, University of Maryland and Tencent AI Lab researchers proposed two new methods:
Router-tuning: Instead of training the whole model, just the router network is fine-tuned on a smaller dataset. This approach cuts down training costs by focusing only on the smaller part of the model that controls which layers to skip.
MindSkip (attention with dynamic depths): MindSkip selectively applies attention to ensure that important layers aren’t skipped, keeping the model’s performance high while improving efficiency. It skips only non-essential layers.
Experiments showed that these approaches achieved:
21% faster processing due to efficient layer-skipping.
Minimal performance drop: Only a 0.2% decrease in performance, making it a small trade-off for the computational gains.
So these adjustments make MoD models both faster and cheaper to train while maintaining nearly the same performance level.
Implementation: Mixture-of-Depths-and-Experts (MoDE)
What if we combine the new MoD approach with the classical MoE? When developing MoD, Google DeepMind, McGill University and Mila researchers also tested this MoD+MoE combination and created Mixture-of-Depths-and-Experts (MoDE) models, aiming to leverage benefits from both approaches.
Two variants of MoDE were tested:
Staged MoDE: First implements MoD, then MoE. In other words, it routes tokens around blocks before the self-attention step, allowing tokens to skip this step when possible.
Integrated MoDE: Combines MoD routing with “no-op” (no operation) experts (a light pathway) alongside standard MLP experts in each block.
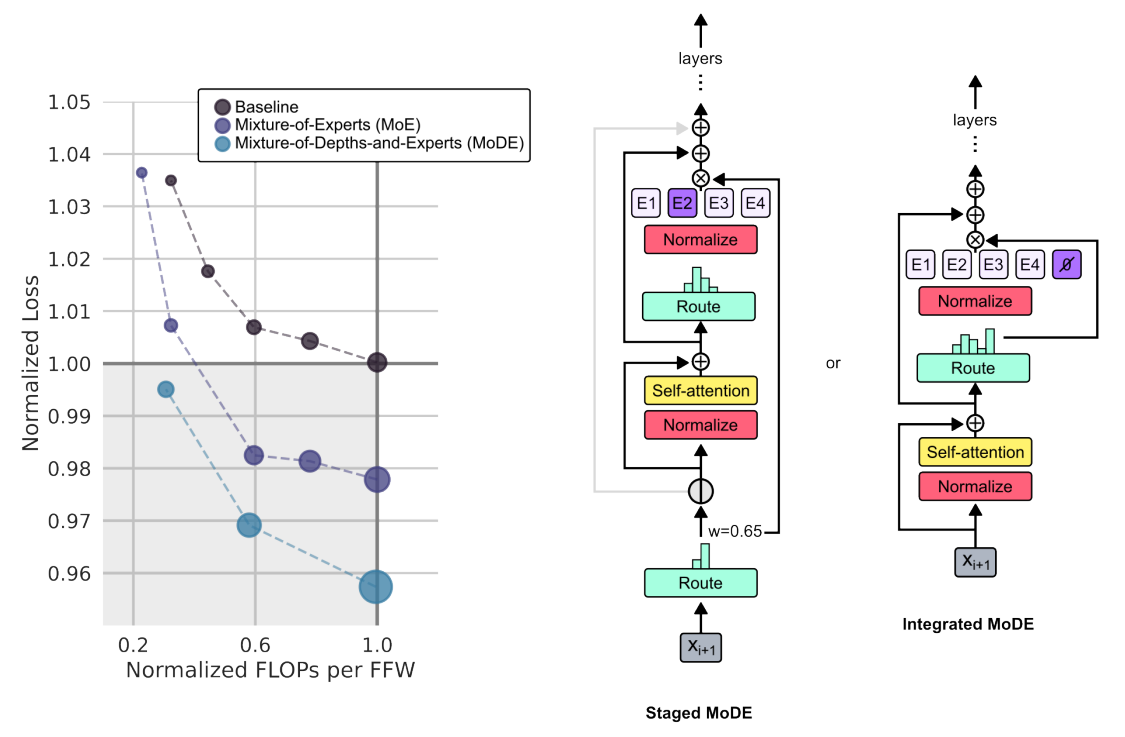
Image Credit: Original paper
Both of these variants have their own advantages:
Staged MoDE is beneficial for skipping the self-attention step, which saves more computation.
Integrated MoDE simplifies the routing and outperforms traditional MoE models. Here, tokens actively learn to select the simpler residual path, rather than being dropped passively due to capacity limits.
Conclusion
In the era when everything become faster and more efficient, we don’t want to waste compute power when it’s not necessary. Both MoD and its MoDE configuration enhance model compute efficiency and performance, with increase of processing speed. MoD gives an option of a more comprehensive and rational view at transformers, and being integrated in MoDE shows particular promise in simplifying the model while preserving high performance.
Bonus: Resources
How did you like it?
Thank you for reading! Share this article with three friends and get a 1-month subscription free! 🤍
