- Turing Post
- Posts
- Topic 17: Inside Les Ministraux
Topic 17: Inside Les Ministraux
we trace Mistral's strategic roadmap and and unpack the unique performance of les Ministraux (Ministral)
Alyona Vert.
November 06, 2024
Previously, in our GenAI Unicorn series, we discussed the rise of French Mistral AI company and their first models, Mistral 7B and Mistral 8×7B. This year, many new Mistral models have been released, demonstrating Mistral’s commitment to rapidly achieving increasingly better performance with their mostly open-source models. Even more notably, Mistral aims to make their models not only powerful but also as small as possible. Join us as we trace Mistral's strategic roadmap, explore their latest breakthroughs, and unpack the unique performance of les Ministraux – small models with outsized capabilities. This piece provides technical insights, practical applications, and everything you need to know about Mistral’s influence on model democratization and edge computing.
In today’s episode, we will cover:
Beginning: From smaller models to larger ones
A shift to specialized models and bigger upgrades
Back to smaller models – why?
What tendencies can we notice through Mistral’s timeline?
Deep dive: how the newest Ministral models work
How good are Ministral models?
Benefits of “Les Ministraux”
Limitations
Implementation
Conclusion
Bonus: All links in one place
Beginning: From smaller models to larger ones
As we wrote before, “This French startup, founded in April 2023 with the ambitious goal of challenging the European Union's technological supremacy, has earned both admiration and skepticism." They act fast and bold. Let’s look at the timeline of Mistral’s releases.
It took them only about five months to introduce their first model! In September 2023, Mistral unveiled Mistral 7B, a compact but powerful language model with 7.3 billion parameters. It surpassed larger models like Llama 2 13B on many benchmarks and matched the performance of Llama 34B in various areas. Grouped-query and sliding window attention were the key innovations, which led to Mistral 7B’s fast, efficient processing and handling of longer sequences with less memory.
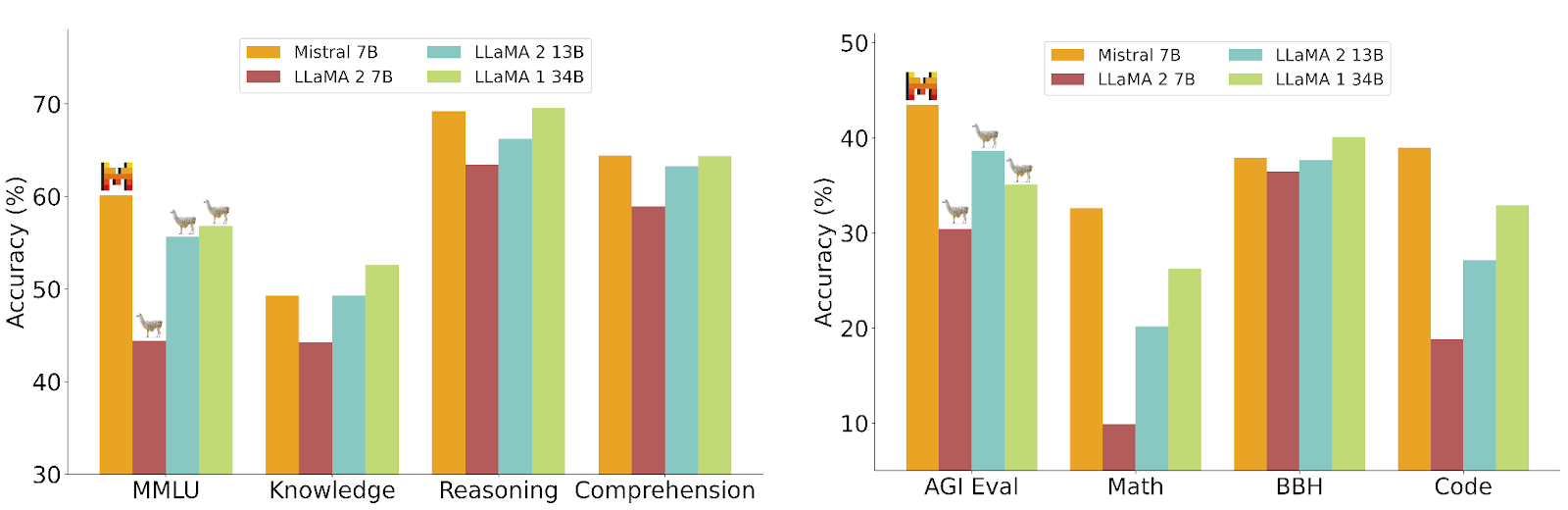
Image Credit: Mistral 7B blog post
A bit later, in December 2023, they launched the Mixtral 8x7B model, a sparse mixture-of-experts (SMoE) with 46.7 billion parameters, using only 12.9 billion per token. Its dynamic routing algorithm made it excel in handling large texts (up to 32K tokens), multiple languages (English, French, Spanish, German, Italian), and code generation, and it was 6x faster than Llama 2 70B. Mixtral 8×7B already demonstrated significantly better performance than their first Mistral 7B.
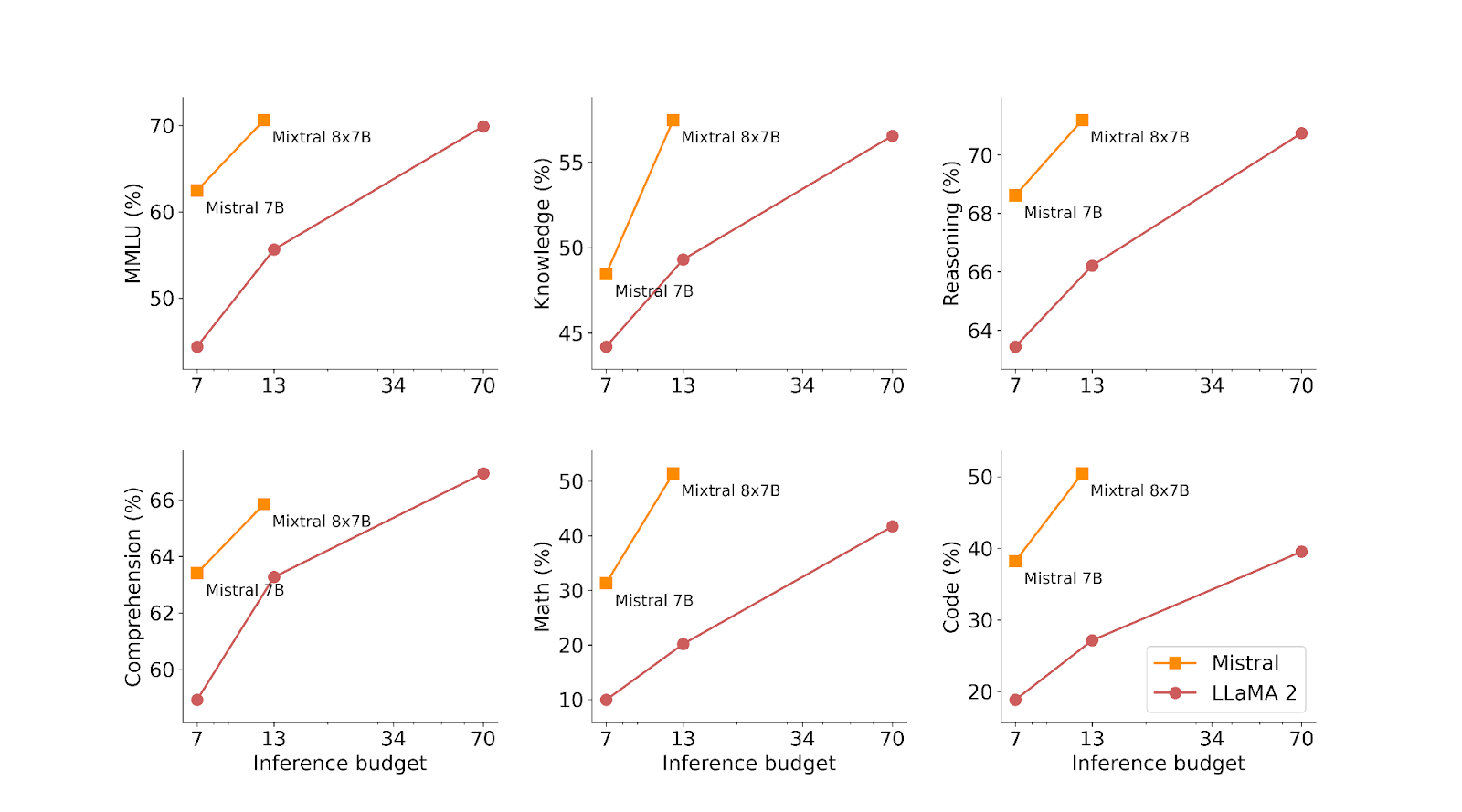
Image Credit: Mixtral of Experts blog post
In February 2024, Mistral introduced its new flagship model, Mistral Large. It excelled in handling complex, multilingual tasks in English, French, Spanish, German, and Italian, with enhanced capabilities in text understanding, transformation, and code generation. Mistral also collaborated with Microsoft to make Mistral Large available through Microsoft Azure, ensuring that powerful AI could be widely accessible.
The small version was developed alongside the large one, optimized for low latency and cost, making it ideal for efficient, real-time applications.
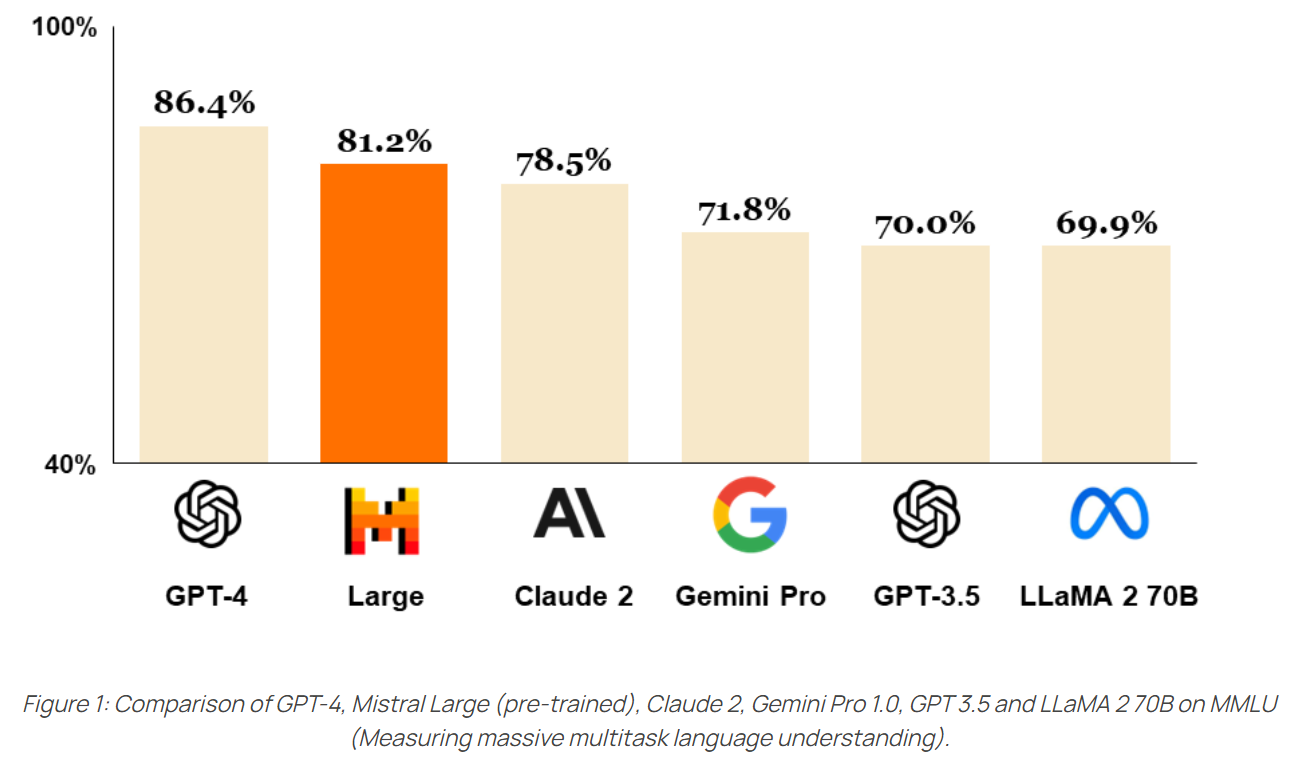
Image Credit: Mistral “Au Large” blog post
In April 2024, Mistral unveiled a new, larger SMoE model, Mixtral 8x22B. This version used only 39 billion active parameters out of 141 billion, and its key strengths were:
multilingual support (English, French, Italian, German, Spanish),
advanced capabilities in math, coding, and function calling,
a 64K token context window for large documents (instead of 32K).
Mixtral 8x22B demonstrated a significant leap in performance compared to its predecessors:
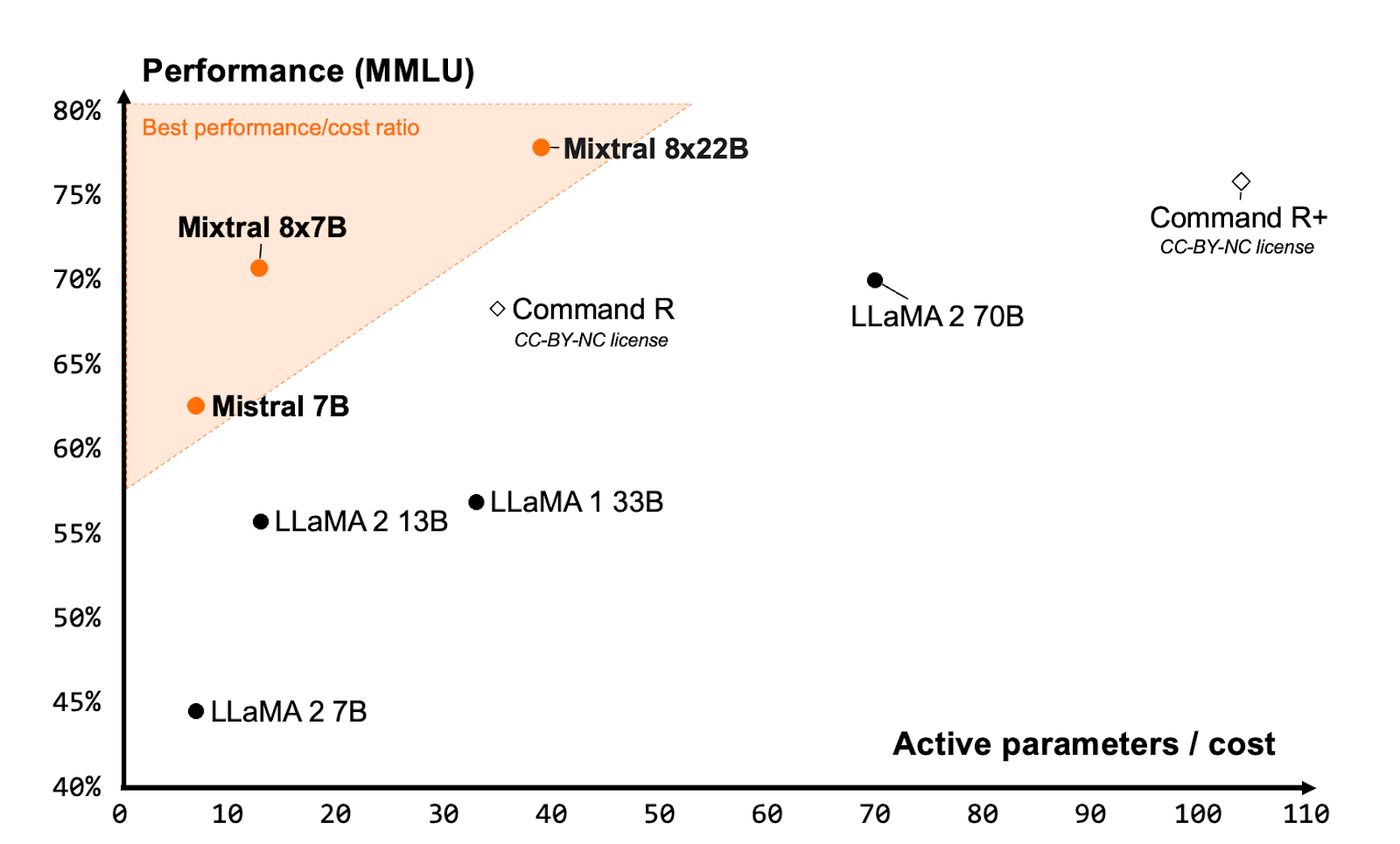
Image Credit: Mistral’s “Cheaper, Better, Faster, Stronger” blog post
A shift to specialized models and bigger upgrades
This article is a must-read for anyone tracking cutting-edge advancements in AI, especially for those interested in how Mistral is reshaping the model landscape with efficiency and agility. Save your time →
Thank you for reading! Share this article with three friends and get a 1-month subscription free! 🤍

Reply