- Turing Post
- Posts
- Topic 10: Inside DeepSeek Models
Topic 10: Inside DeepSeek Models
We discuss the innovation suggested by the DeepSeek team, how it improves the models' performance, and dive into the architectures and implementation of the models
Ksenia Se & Alyona Vert.
August 28, 2024
Introduction
The DeepSeek family of models presents a fascinating case study, particularly in open-source development. While much attention in the AI community has been focused on models like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves closer examination.
Coming from China, DeepSeek's technical innovations are turning heads in Silicon Valley. Their revolutionary approaches to attention mechanisms and the Mixture-of-Experts (MoE) technique have led to impressive efficiency gains. This is exemplified in their DeepSeek-V2 and DeepSeek-Coder-V2 models, with the latter widely regarded as one of the strongest open-source code models available. Another surprising thing is that DeepSeek small models often outperform various bigger models. These innovations highlight China's growing role in AI, challenging the notion that it only imitates rather than innovates, and signaling its ascent to global AI leadership. DeepSeek is also quite affordable. Let’s explore the specific models in the DeepSeek family and how they manage to do all the above.
In today’s episode, we will cover:
In the race to beat the benchmarks
New stage: DeepSeek innovates to beat challenges, not benchmarks
Strategies behind DeepSeekMoE that make the difference
DeepSeek-V2: How does it work?
Advantages and limitations of DeepSeek-V2
DeepSeek-Coder: What makes it highly efficient?
Implementation of DeepSeek-Coder-V2
Pricing
Conclusion
Bonus: Resources
In the race to beat the benchmarks
DeepSeek models quickly gained popularity upon release. Initially, DeepSeek created their first model with architecture similar to other open models like LLaMA, aiming to outperform benchmarks. This approach set the stage for a series of rapid model releases.
On November 2, 2023, DeepSeek began rapidly unveiling its models, starting with DeepSeek Coder. From the outset, it was free for commercial use and fully open-source.
Introducing DeepSeek Coder!
- SOTA large coding models with params ranging from 1.3B to 33B.
- Building games, testing code, fixing bugs, and analyzing data... You dream it, we make it.
- Free for commercial use and fully open-source.
Try it out now at deepseekcoder.github.io— DeepSeek (@deepseek_ai)
3:52 PM • Nov 2, 2023
Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described as the “next frontier of open-source LLMs,” scaled up to 67B parameters.
🚀Launching DeepSeek LLM! Next Frontier of Open-Source LLMs! #DeepSeekLLM
🧠Up to 67 billion parameters, astonishing in various benchmarks.
🔍Crafted with 2 trillion bilingual tokens.
🌐Open Source! DeepSeek LLM 7B/67B Base&Chat released.🔗Try out here:
— DeepSeek (@deepseek_ai)
2:44 PM • Nov 29, 2023
As we've already noted, DeepSeek LLM was developed to compete with other LLMs available at the time. DeepSeek LLM 67B Chat had already demonstrated significant performance, approaching that of GPT-4. But, like many models, it faced challenges in computational efficiency and scalability. This led the DeepSeek AI team to innovate further and develop their own approaches to solve these existing problems.
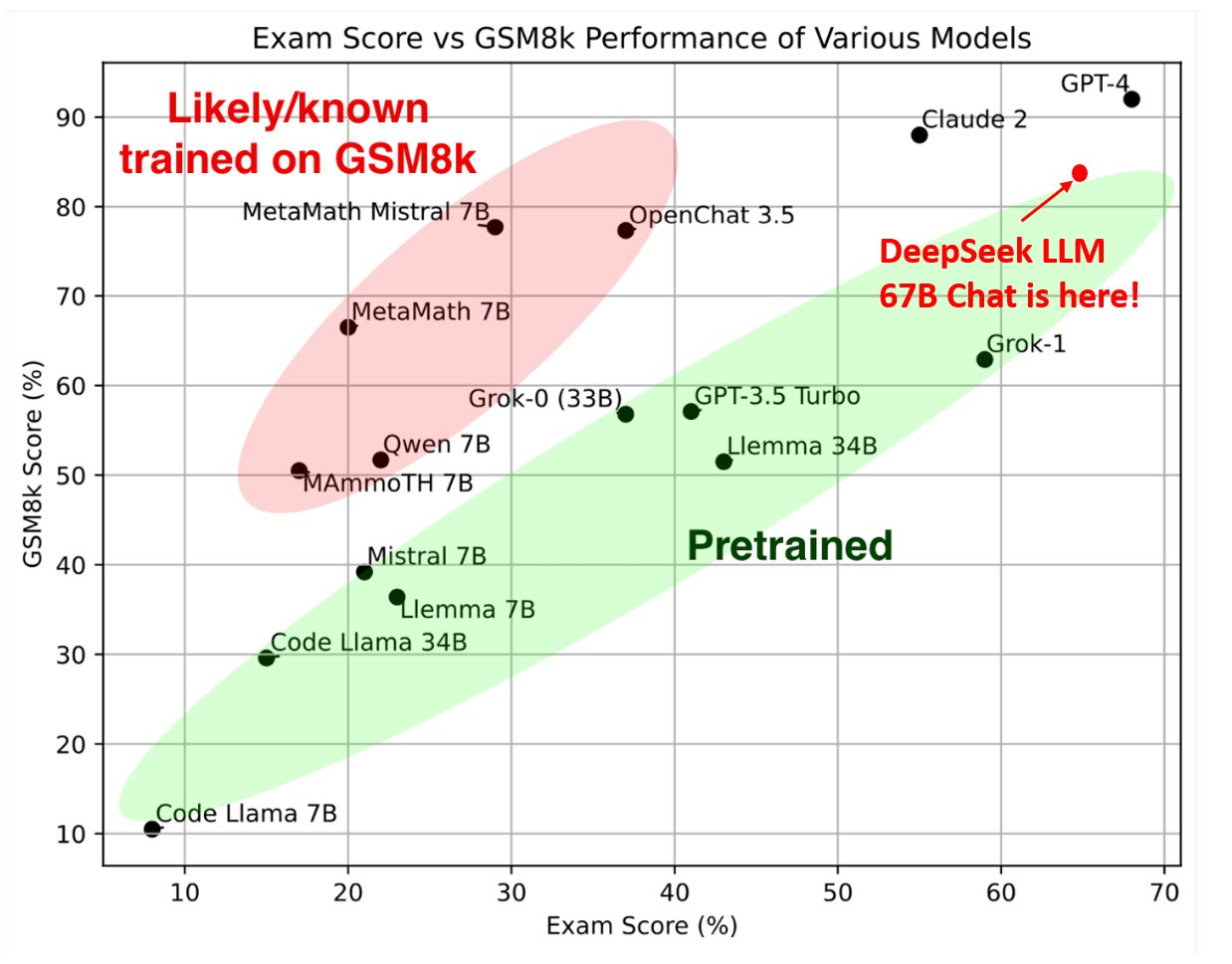
Image Credit: DeepSeek’s Twitter
New stage: DeepSeek innovates to beat challenges, not benchmarks
In only two months, DeepSeek came up with something new and interesting.
In January 2024, this resulted in the creation of more advanced and efficient models like DeepSeekMoE, which featured an advanced Mixture-of-Experts architecture, and a new version of their Coder, DeepSeek-Coder-v1.5. With fewer activated parameters, DeepSeekMoE could achieve performance comparable to LLaMA 2 7B.
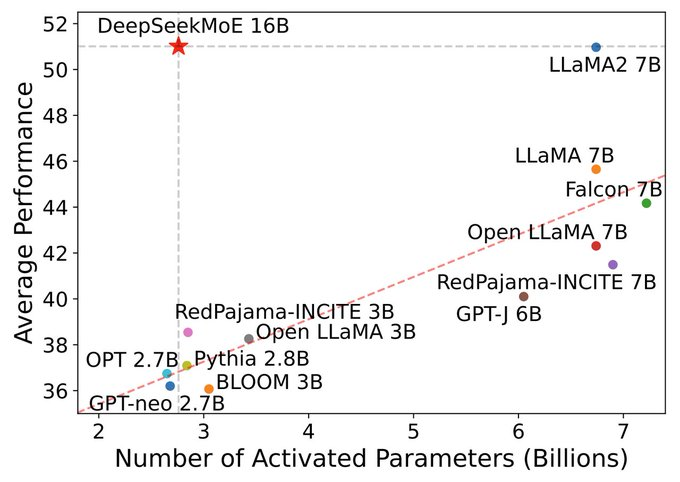
Image Credit: DeepSeek AI’s Twitter
In February 2024, DeepSeek introduced a specialized model, DeepSeekMath, with 7B parameters. This smaller model approached the mathematical reasoning capabilities of GPT-4 and outperformed another Chinese model, Qwen-72B.
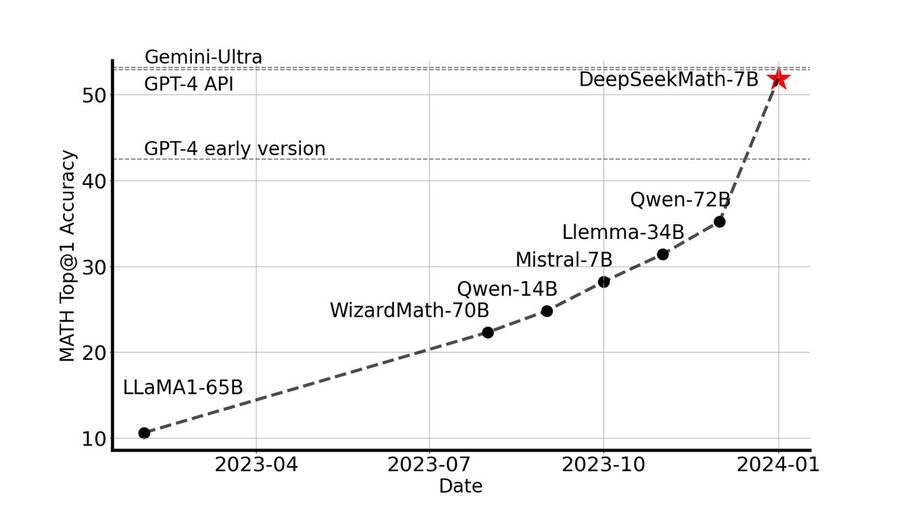
Image Credit: “DeepSeekMath” paper
Later in March 2024, DeepSeek tried their hand at vision models and introduced DeepSeek-VL for high-quality vision-language understanding. With this model, DeepSeek AI showed it could efficiently process high-resolution images (1024x1024) within a fixed token budget, all while keeping computational overhead low. This means they successfully overcame the previous challenges in computational efficiency!
Since May 2024, we have been witnessing the development and success of DeepSeek-V2 and DeepSeek-Coder-V2 models. Both are built on DeepSeek’s upgraded Mixture-of-Experts approach, first used in DeepSeekMoE. DeepSeek-V2 brought another of DeepSeek’s innovations – Multi-Head Latent Attention (MLA), a modified attention mechanism for Transformers that allows faster information processing with less memory usage.
DeepSeek-Coder-V2 is the first open-source AI model to surpass GPT4-Turbo in coding and math, which made it one of the most acclaimed new models. This time developers upgraded the previous version of their Coder and now DeepSeek-Coder-V2 supports 338 languages and 128K context length.
The freshest model, released by DeepSeek in August 2024, is an optimized version of their open-source model for theorem proving in Lean 4, DeepSeek-Prover-V1.5. By refining its predecessor, DeepSeek-Prover-V1, it uses a combination of supervised fine-tuning, reinforcement learning from proof assistant feedback (RLPAF), and a Monte-Carlo tree search variant called RMaxTS. These methods improved its performance on mathematical benchmarks, achieving pass rates of 63.5% on the high-school level miniF2F test and 25.3% on the undergraduate-level ProofNet test, setting new state-of-the-art results.
It’s been just a half of a year and DeepSeek AI startup already significantly enhanced their models. Impressive speed. Let's examine the innovative architecture under the hood of the latest models.
Strategies behind DeepSeekMoE that make the difference
DeepSeekMoE is implemented in the most powerful DeepSeek models: DeepSeek V2 and DeepSeek-Coder-V2. What problems does it solve?
Traditional Mixture of Experts (MoE) architecture divides tasks among multiple expert models, selecting the most relevant expert(s) for each input using a gating mechanism. This approach allows models to handle different aspects of data more effectively, improving efficiency and scalability in large-scale tasks. But it struggles with ensuring that each expert focuses on a unique area of knowledge. DeepSeekMoE is an advanced version of the MoE architecture designed to improve how LLMs handle complex tasks. It involves two main strategies:
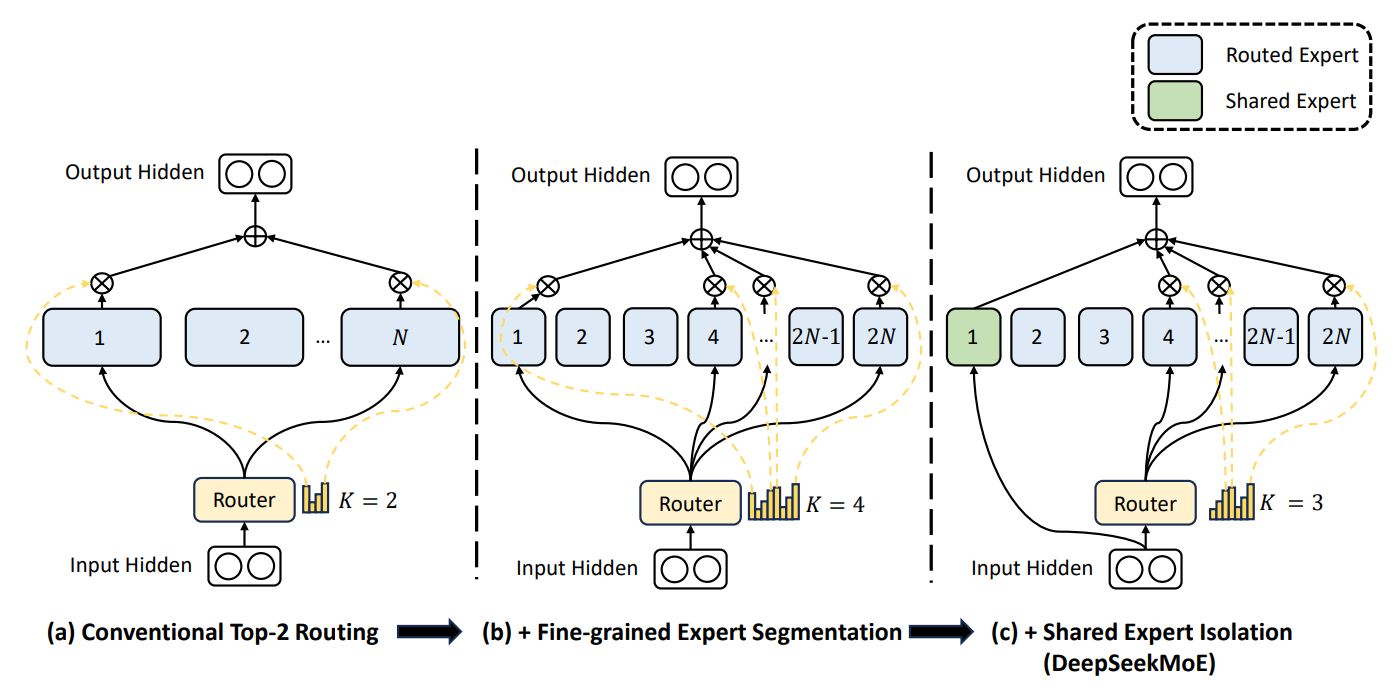
Image Credit: “DeepSeekMoE” paper
Fine-grained expert segmentation: DeepSeekMoE breaks down each expert into smaller, more focused parts. The router is a mechanism that decides which expert (or experts) should handle a specific piece of information or task. When data comes into the model, the router directs it to the most appropriate experts based on their specialization. This ensures that each task is handled by the part of the model best suited for it.
Shared expert isolation: Shared experts are specific experts that are always activated, regardless of what the router decides. They handle common knowledge that multiple tasks might need. By having shared experts, the model doesn't need to store the same information in multiple places. This reduces redundancy, ensuring that other experts focus on unique, specialised areas.
By implementing these strategies, DeepSeekMoE enhances the efficiency of the model, allowing it to perform better than other MoE models, especially when handling larger datasets.
DeepSeek-V2: How does it work?
DeepSeek-V2 is a state-of-the-art language model that uses a Transformer architecture combined with an innovative MoE system and a specialized attention mechanism called Multi-Head Latent Attention (MLA).

Image Credit: “DeepSeek-V2” paper
Here is how each part works:
Transformer architecture: At its core, DeepSeek-V2 uses the Transformer architecture, which processes text by splitting it into smaller tokens (like words or subwords) and then uses layers of computations to understand the relationships between these tokens.
Mixture-of-Experts (MoE): Instead of using all 236 billion parameters for every task, DeepSeek-V2 only activates a portion (21 billion) based on what it needs to do. This makes it more efficient because it doesn't waste resources on unnecessary computations. MoE in DeepSeek-V2 works like DeepSeekMoE which we’ve explored earlier.
Multi-Head Latent Attention (MLA): In a Transformer, attention mechanisms help the model focus on the most relevant parts of the input. This usually involves storing a lot of data, Key-Value cache or or KV cache, temporarily, which can be slow and memory-intensive. DeepSeek-V2 introduces Multi-Head Latent Attention (MLA), a modified attention mechanism that compresses the KV cache into a much smaller form. This allows the model to process information faster and with less memory without losing accuracy.
Combination of these innovations helps DeepSeek-V2 achieve special features that make it even more competitive among other open models than previous versions. Let’s take a look at the advantages and limitations.
Advantages of DeepSeek-V2
Sparse computation due to usage of MoE.
Faster inference because of MLA.
Lower training costs: DeepSeek V2 saves about 42.5% in training costs compared to its predecessor, DeepSeek 67B.
High throughput: DeepSeek V2 achieves a throughput that is 5.76 times higher than DeepSeek 67B. So it’s capable of generating text at over 50,000 tokens per second on standard hardware.
Managing extremely long text inputs up to 128,000 tokens.
Excels in both English and Chinese language tasks, in code generation and mathematical reasoning.
However, such a complex large model with many involved parts still has several limitations.
Limitations of DeepSeek-V2
Sophisticated architecture with Transformers, MoE and MLA.
Risk of losing information while compressing data in MLA.
Training requires significant computational resources because of the vast dataset.
Risk of biases because DeepSeek-V2 is trained on vast amounts of data from the internet.
Now to another DeepSeek giant, DeepSeek-Coder-V2!
DeepSeek-Coder-V2: What makes it highly efficient?
What is behind DeepSeek-Coder-V2, making it so special to beat GPT4-Turbo, Claude-3-Opus, Gemini-1.5-Pro, Llama-3-70B and Codestral in coding and math?
DeepSeek-Coder-V2, costing 20-50x times less than other models, represents a significant upgrade over the original DeepSeek-Coder, with more extensive training data, larger and more efficient models, enhanced context handling, and advanced techniques like Fill-In-The-Middle and Reinforcement Learning. Let’s explore everything in order.
Training data: Compared to the original DeepSeek-Coder, DeepSeek-Coder-V2 expanded the training data significantly by adding an additional 6 trillion tokens, increasing the total to 10.2 trillion tokens. It’s trained on 60% source code, 10% math corpus, and 30% natural language. 1,170 B of code tokens were taken from GitHub and CommonCrawl. DeepSeek-Coder-V2 uses the same pipeline as DeepSeekMath.
Expanded language support: DeepSeek-Coder-V2 supports a broader range of 338 programming languages.
Model size and architecture: The DeepSeek-Coder-V2 model comes in two main sizes: a smaller version with 16 B parameters and a larger one with 236 B parameters. The larger model is more powerful, and its architecture is based on DeepSeek's MoE approach with 21 billion "active" parameters. This makes the model faster and more efficient.
Handling long contexts: DeepSeek-Coder-V2 extends the context length from 16,000 to 128,000 tokens, allowing it to work with much larger and more complex projects. This means V2 can better understand and manage extensive codebases.
Fill-In-The-Middle (FIM): One of the special features of this model is its ability to fill in missing parts of code. For instance, if you have a piece of code with something missing in the middle, the model can predict what should be there based on the surrounding code.
Reinforcement Learning: The model utilizes a more sophisticated reinforcement learning approach, including Group Relative Policy Optimization (GRPO), which uses feedback from compilers and test cases, and a learned reward model to fine-tune the Coder. This leads to better alignment with human preferences in coding tasks.
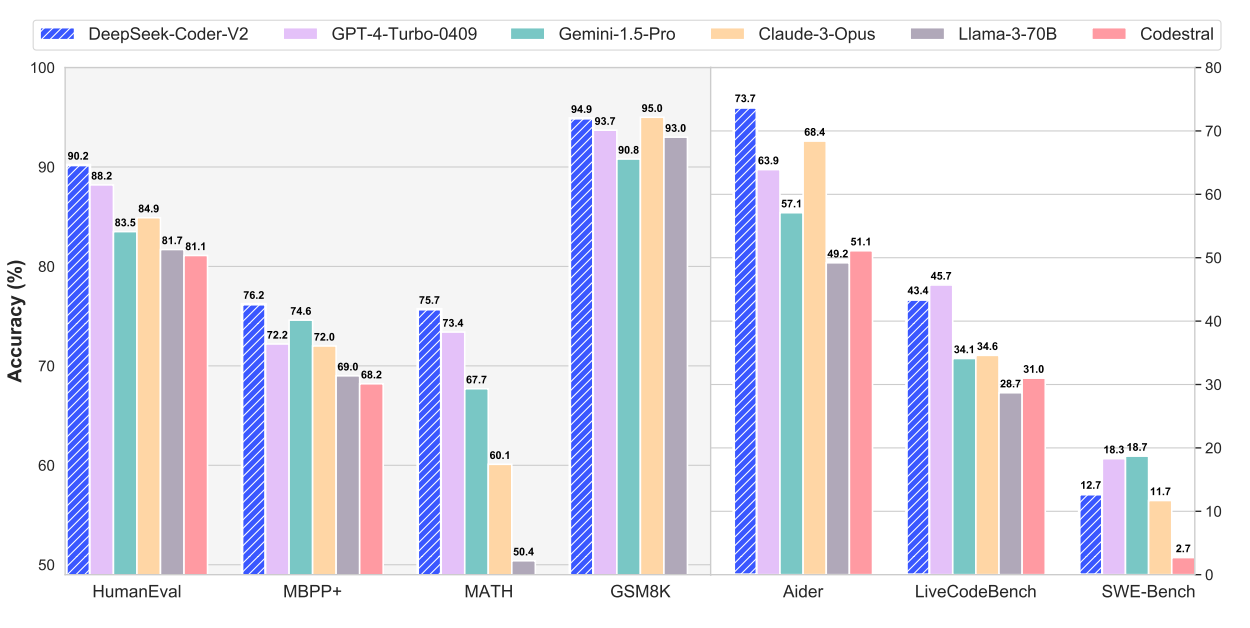
The performance of DeepSeek-Coder-V2 on math and code benchmarks. Image Credit: “DeepSeek-Coder-V2” paper
These features together with basing on successful DeepSeekMoE architecture lead to the following results in implementation.
Implementation of DeepSeek-Coder-V2
Testing DeepSeek-Coder-V2 on various benchmarks shows that DeepSeek-Coder-V2 outperforms most models, including Chinese competitors. It has high score even in Arena-Hard leaderboard:
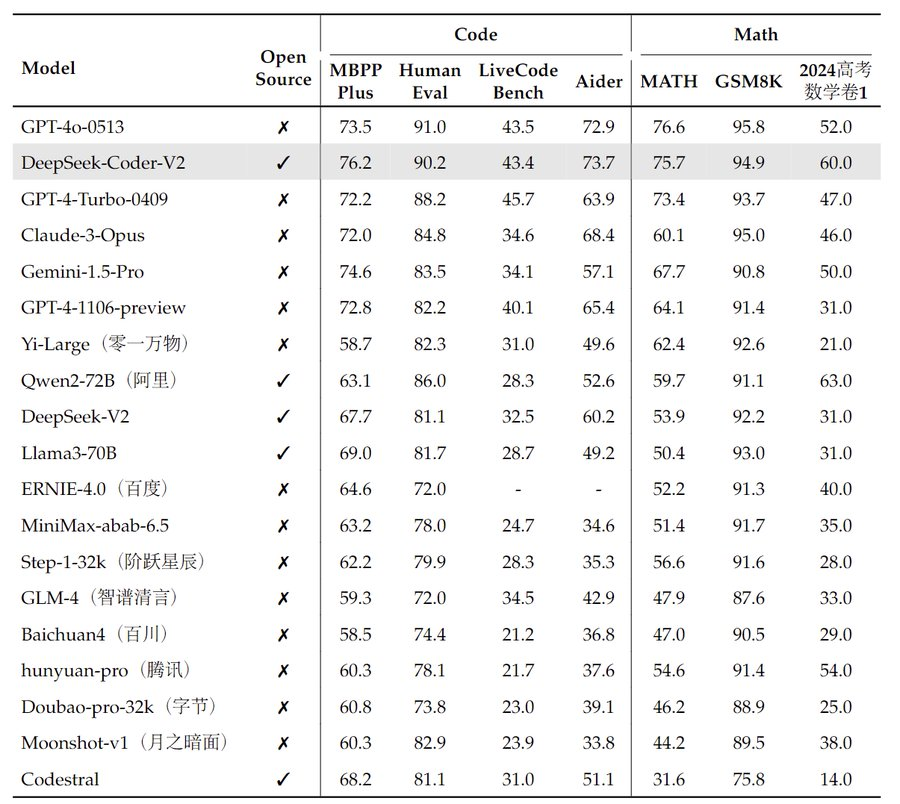
Image Credit: DeepSeek’s Twitter
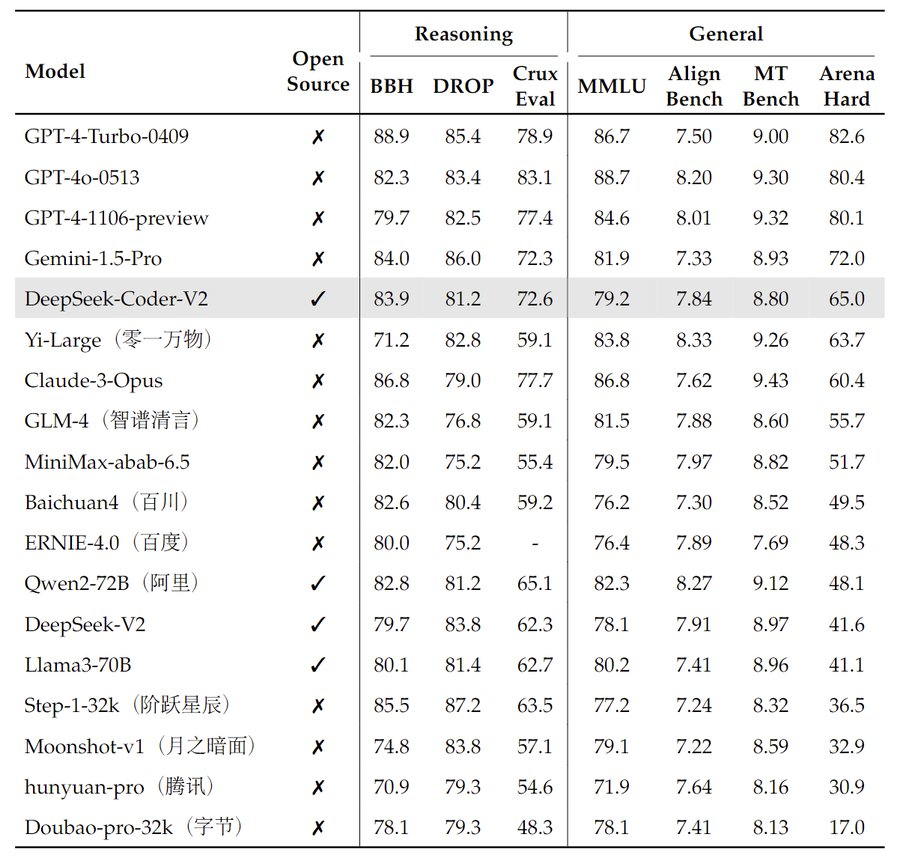
Image Credit: DeepSeek’s Twitter
In code editing skill DeepSeek-Coder-V2 0724 gets 72,9% score which is the same as the latest GPT-4o and higher than any other models except for the Claude-3.5-Sonnet with 77,4% score.
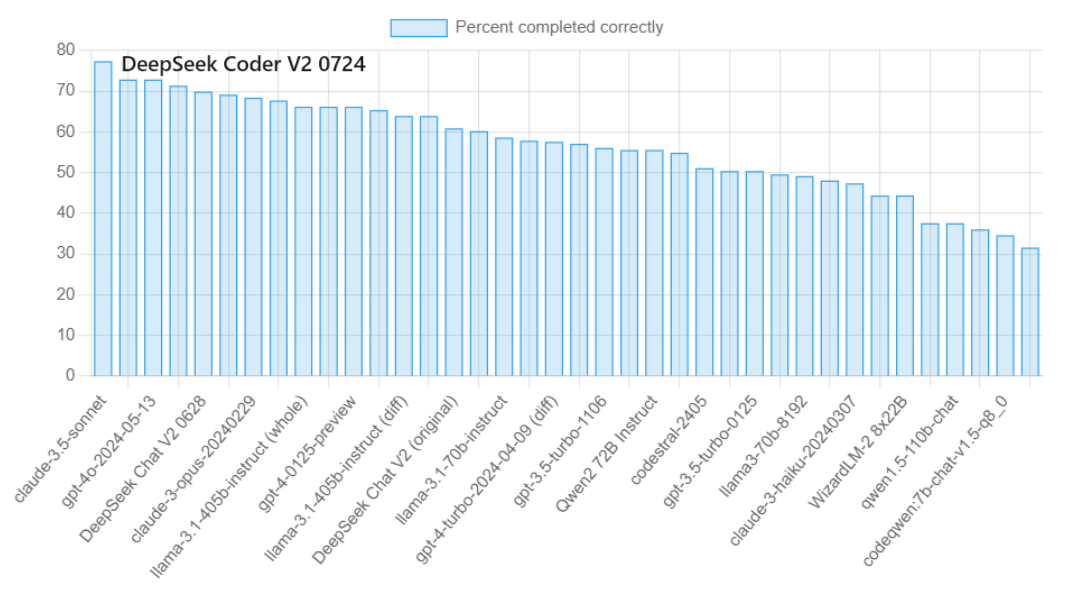
Image Credit: Aider Leaderboard
The large 236B DeepSeek coder V2 also demonstrates impressive speed, running at 25 toks/sec on a single M2 Ultra:
The 236B DeepSeek coder V2 runs at 25 toks/sec on a single M2 Ultra. Not bad for such a large model:
— Awni Hannun (@awnihannun)
9:12 PM • Jul 18, 2024
Pricing
It’s quite affordable.

Image Credit: DeepSeek website
Conclusion
We have explored DeepSeek’s approach to the development of advanced models. Their initial attempt to beat the benchmarks led them to create models that were rather mundane, similar to many others. But then they pivoted to tackling challenges instead of just beating benchmarks. That decision was certainly fruitful, and now the open-source family of models, including DeepSeek Coder, DeepSeek LLM, DeepSeekMoE, DeepSeek-Coder-V1.5, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, and DeepSeek-Prover-V1.5, can be utilized for many purposes and is democratizing the usage of generative models. It’s interesting how they upgraded the Mixture-of-Experts architecture and attention mechanisms to new versions, making LLMs more versatile, cost-effective, and capable of addressing computational challenges, handling long contexts, and working very quickly. The most popular, DeepSeek-Coder-V2, remains at the top in coding tasks and can be run with Ollama, making it particularly attractive for indie developers and coders. Chinese models are making inroads to be on par with American models.
Bonus: Resources
DeepSeek website: https://www.deepseek.com/
DeepSeek LLM Scaling Open-Source Language Models with Longtermism https://arxiv.org/pdf/2401.02954
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models https://arxiv.org/pdf/2401.06066
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model https://arxiv.org/pdf/2405.04434
DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence https://arxiv.org/pdf/2401.14196
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence https://arxiv.org/pdf/2406.11931
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeek-VL: Towards Real-World Vision-Language Understanding https://arxiv.org/pdf/2403.05525
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data https://arxiv.org/pdf/2405.14333
Thank you for reading! Share this article with three friends and get a 1-month subscription free! 🤍
Reply