- Turing Post
- Posts
- Computer Vision in the 1980s: The Quiet Decade of Key Advancements
Computer Vision in the 1980s: The Quiet Decade of Key Advancements
From merely describing the physiological properties of visual cells to translating visual processing into algorythms
Ksenia Se & Valeriia Kuka
April 24, 2024
Introduction
In the previous episode, we unfolded the first attempts that laid the groundwork for today’s sophisticated computer vision (CV) systems. Today, we are focusing on the 1980s – a quiet decade without major implementation breakthroughs but marked by foundational advancements that set the stage for such things as self-driving cars, face recognition techniques and 3D mapping.
Information about the 1980s is relatively scarce so we had to dig into various reports from the Commerce Department and other agencies. During these years, computer vision gradually advanced from experimental beginnings to more developed applications. The decade was marked by research into complex functions like object recognition, scene interpretation, and motion detection. While the field made significant progress, challenges in reliability and theoretical models’ application to practical uses remained prominent.
For you, we’ve pieced together a picture of a field making gradual but crucial progress. It was also the times, when CV tech entered the commercial sector. Let’s dive in!
In this episode, we will explore:
Edge Detection and Low-Level Processing
Stereo Vision
Commercial applications
Challenges in Vision Systems
Reaction to challenges
Who’s funding this?
Artificial intelligence steps in
Conclusion
Computer Vision in the early 1980s
In the early 1980s, computer vision was still a nascent field characterized by rudimentary technologies and a lack of established principles. Research predominantly focused on basic elements such as edge detection and low-level processing necessary for advancing more complex functions like object recognition and scene interpretation. Despite the advancements and expansion of commercial applications, the reliability of edge detection methods remained inconsistent, limiting their application and highlighting ongoing challenges in the field. This era underscored the computational demands and the complexity of adapting theoretical models to practical applications, with successes mostly confined to controlled industrial settings and general-purpose systems remaining elusive due to their high development costs and limited flexibility.
Edge Detection and Low-Level Processing
During the early era of computer vision, the field was polarized by two influential theories. On one side, Hubel & Wiesel (1962) posited that the visual cortex functions through feature detectors, an idea that emphasized detecting specific visual elements. Conversely, Campbell & Robson (1968) argued for a model where the visual cortex acts similarly to a spatial Fourier analyzer, processing visual information through multiple, independent orientation and spatial-frequency-tuned channels.
In 1980, Kunihiko Fukushima introduced the "neocognitron," a self-organizing neural network model capable of position-invariant pattern recognition. This network, which learns without a teacher, mimics the hierarchical structure of the visual nervous system, as proposed by Hubel and Wiesel. It consists of multiple layers, including S-cells and C-cells, which are similar to the simple and complex cells of the visual cortex. Fukushima’s neocognitron adjusted its synaptic weights through unsupervised learning, progressively organizing itself to recognize visual patterns based on their shape, regardless of position shifts or slight distortions.
David Marr and Ellen Hildreth at MIT's Artificial Intelligence Laboratory, on the other hand, moved beyond the previous theories and showed that both lines of thought have limitations. David Marr, a luminary professor who advocated for computational methods in vision research, was an advisor of Ellen Hildreth, a master's student at that time. Published in 1980, thier work, “Theory of Edge Detection”, was the last publication for Marr during his life and a foundation of Hildreth’s Master Thesis “Implementation of a Theory of Edge Detection.”

Image Credit: “Theory of Edge Detection”
Central to their theory was Marr’s concept of the "Primal Sketch," a framework designed to abstract the essential structural elements of a visual scene. This concept is divided into two levels:
The Raw Primal Sketch captures basic visual features like edges, lines, bars, terminations, and blobs.
The Full Primal Sketch synthesizes these elements into a coherent structure, grouping related features and identifying the boundaries of distinct objects.
This approach offered a new, task-oriented model for visual processing that could be translated into algorithms for machine use. This was one of the first descriptions of the visual processing, instead of merely describing the physiological properties of visual cells.
Although that development was influential, there was no consensus on a singular best method for edge detection; techniques like Marr and Hilbert's method was considered promising, but overall, edge detectors were unreliable and typically application-specific.
Stereo Vision
Research on stereo vision, which aims to extract 3D information from two or more 2D views of a scene, made some progress in the 1980s. One notable contribution was the paper "An Iterative Image Registration Technique with an Application to Stereo Vision" (1981) by Bruce D. Lucas and Takeo Kanade. They presented a novel image registration technique that leveraged the spatial intensity gradient of images for efficient matching, inspired by the Newton-Raphson method. This method significantly reduced the computational cost by limiting the number of potential matches explored compared to traditional exhaustive methods.
Lucas and Kanade demonstrated their technique within a stereo vision system, where it offered a substantial improvement in processing speed and flexibility over previous methods. By efficiently identifying corresponding points between two stereo images, their method allowed for more accurate depth estimation and 3D reconstruction. This work laid the foundation for further advancements in stereo vision and promised improvements in applications like robotics, autonomous navigation, and 3D mapping.
The 1980s were overall very productive for Takeo Kanade; we recommend you get to know his work during these years (here from page 52 to 64).
Edge detection was still a work in progress in the 80s, and that made it harder for stereo vision systems to do their thing reliably. Matching up the right points between images to figure out depth was a hurdle, but researchers were figuring it out bit by bit!
Commercial applications
Computer vision technology has begun to make inroads into the commercial sector. By 1984, according to “An overview of artificial intelligence and robotics: volume 1”, a dozen companies currently offered advanced vision systems for industrial applications. These systems perform effectively in controlled environments, addressing specific tasks such as verification, inspection, object recognition, and determining object location and orientation. However, current commercial offerings primarily focused on two-dimensional data analysis. As we’ve mentioned, recognizing objects from various viewpoints, which necessitates 3D understanding, remained a challenge for these systems.

Image Credit: “An overview of Computer Vision”, 1982
Challenges in Vision Systems
Reliability and Effectiveness: The success of higher-level processes like image segmentation and model-based vision systems hinges on the reliability of edge detection. Image segmentation approaches have been unreliable when used directly. Some progress has been achieved by combining segmentation with interpretation; however, these methods generally require prior knowledge of the objects involved, limiting their applicability in general-purpose vision systems.
Industrial Applications: Specialized industrial setups with custom lighting and camera configurations have achieved success in simple contexts by simplifying edge detection and segmentation. However, these systems struggle in more complex environments, often showing limited flexibility and a shallow grasp of deeper challenges.
Computational Demands and Complexity: Vision systems encounter significant computational demands due to the need for sophisticated algorithms capable of processing the extensive data contained in images. The inherent ambiguity of translating visual data to real-world scenarios and the variability in how objects appear introduce further complexities. As a result, developing adaptable, general-purpose vision systems remains a big challenge. These systems often end up restricted to specific, narrowly defined tasks, making each new implementation costly and time-consuming.
Takeo Kanade and Raj Reddy in their paper “Computer vision: the challenge of imperfect inputs” (1983) argued that the current systems struggled with depth perception and object overlap, relying heavily on controlled conditions to function. These systems typically followed a three-step process: detecting features, deriving real-world object shapes, and recognizing objects based on stored models. Advances like stripe lighting have simplified shape recognition in industrial settings, but broader applications remained limited and required more computational power and sophisticated algorithms.
Reaction to challenges
In response to these and other challenges, the Conference on Computer Vision and Pattern Recognition (CVPR) was founded in 1983 by Takeo Kanade and Dana Ballard. The inaugural CVPR conference took place from June 19 to 23, 1983, in Washington, DC, and featured 59 oral presentations and 58 poster papers, setting a precedent for rigorous academic exchange and community building. There was a lot of excitement and will to move forward, nonetheless the hurdles with lack of compute and nascency of research.
Since its inception, CVPR has grown significantly, becoming one of the most pivotal gatherings for computer vision researchers and industry professionals. The conference is known for its high selectivity, maintaining an acceptance rate below 30% for papers and under 5% for oral presentations.
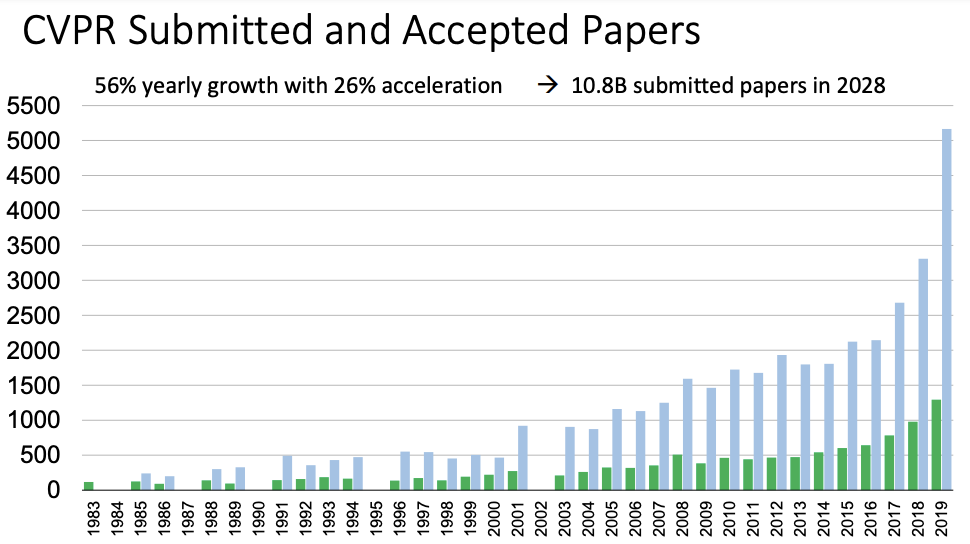
Image Credit: CVPR Statistics
Who’s funding this?
In the early 1980s, funding for computer vision research was predominantly sourced from various branches of the U.S. Government, as detailed in the 1982 report, “An Overview of Computer Vision,” prepared for NASA. This period saw significant financial commitment to developing technologies that spanned multiple applications from autonomous navigation to medical imaging.
DARPA (Defense Advanced Research Projects Agency): Annually contributing approximately $2.5 million, DARPA's funding supported areas such as automatic stereo, terrain mapping, autonomous navigation, and robot vision. They facilitated several image-understanding laboratories at universities.
DMA (Defense Mapping Agency): With a focus on achieving "fully automated" mapping by 1995, DMA actively collaborated with DARPA to develop and evaluate vision techniques in cartography, investing in expert systems for applying research results.
NSF (National Science Foundation): The National Science Foundation allocated roughly $1.5 million annually across various computer vision topics.
NIH (National Institutes of Health): Concentrating on medical research applications, NIH dedicated around $1-2 million annually to obtain and evaluate health-related images.
NASA (National Aeronautics and Space Administration): While spending about $100 million on image processing, NASA’s direct investment in computer vision was under $1 million, mainly supporting research at the Jet Propulsion Laboratory for robot manipulation systems.
NBS (National Bureau of Standards): Conducting in-house robotics vision research, the National Bureau of Standards had an annual budget of approximately half a million dollars.
Other Government Agencies and Contractors: An estimated $1-2 million was contributed by various government agencies and contractors through IRAD funds linked to prime contracts annually.
Artificial intelligence steps in
By the mid-1980s, despite extensive research into high-level vision systems, a versatile, general-purpose system had not yet emerged. Notable ongoing projects mentioned in “An overview of artificial intelligence and robotics: volume 1” included ACRONYM at Stanford University, VISIONS at the University of Massachusetts, and the robotic vision project at the National Bureau of Standards (NBS). Unfortunately, these projects did not have easily accessible links online.
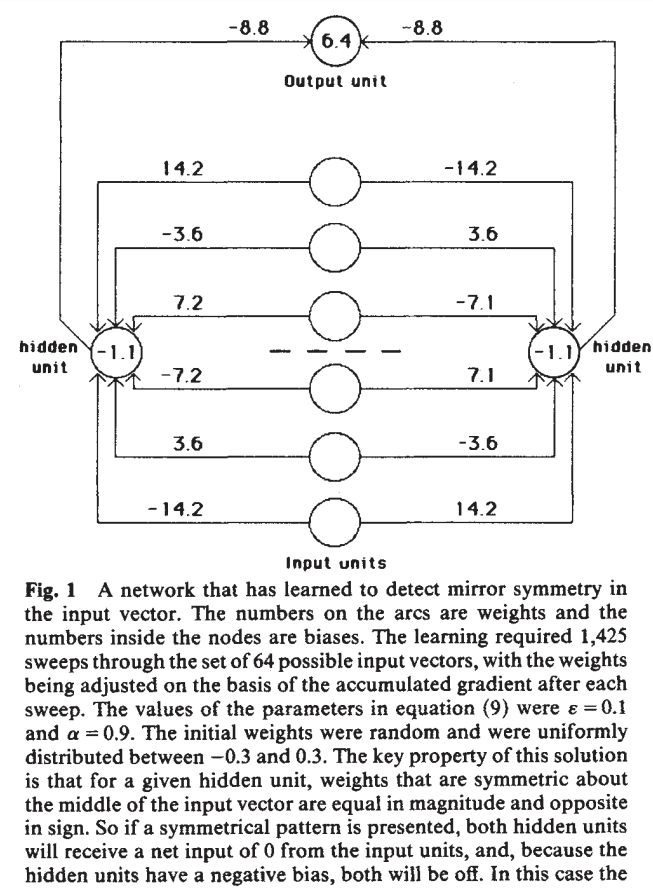
Image Credit: “Learning representations by back-propagating errors”
As artificial intelligence neared a low point during the winter of 1987, pivotal developments the year prior began to reshape the landscape. In 1986, David Rumelhart, Geoffrey Hinton, and Ronald Williams popularized error backpropagation in "Learning representations by back-propagating errors," setting the stage for the neural networks' resurgence in the 21st century.
Simultaneously, in 1987, Brown University mathematicians Lawrence Sirovich and Michael Kirby introduced "eigenfaces" using principal component analysis in "Low-dimensional Procedure for the Characterization of Human Faces." This method later informed Matthew Turk and Alex Pentland's 1991 approach to face detection/recognition at MIT. That same year, cognitive scientist Irving Biederman proposed the "Recognition-by-components" theory, suggesting objects are recognized by identifying their constituent "geons."
In 1988, the "active contour model" or "snakes" were developed by Michael Kass, Andrew Witkin, and Demetri Terzopoulos, revolutionizing boundary detection in images by adapting to changing object outlines, a significant advancement over static methods.
John Canny further enhanced edge detection technology in 1986 with the Canny Edge Detector, which provided an optimal balance between detection accuracy and error minimization, applicable across varying imaging conditions.
The decade closes with Yann LeCun demonstrating the practical use of backpropagation in convolutional neural networks at Bell Labs in 1989, pioneering the recognition of handwritten digits and proving the effectiveness of neural networks in real-world applications.
Conclusion
The 1980s in computer vision was a period of essential groundwork, despite not yielding the expected breakthroughs. It was a time when foundational techniques were developed and critical discussions began, setting the stage for later advancements. Forums like the CVPR emerged, promoting collaboration that would drive future innovation. Reflecting on this decade, we recognize its role in shaping the sophisticated computer vision technologies we utilize today, illustrating how steady progress can quietly lead to significant results.
/Next episode: Recognizing smiles in 1990s
How did you like it? |
If you want to get access to this and other articles, please share with your friends and colleagues and receive one month of Premium subscription for free 🤍
Reply