- Turing Post
- Posts
- Token 1.17: Deploying ML Model: Best practices feat. LLMs
Token 1.17: Deploying ML Model: Best practices feat. LLMs
Unless you are a researcher whose sole job is to beat benchmarks at some predefined dataset, you will want to deploy your model
Bhuwan Bhatt
January 17, 2024
The spotlight in AI has recently shifted towards foundation models (FMs) and their subset – large language models (LLMs). Despite this trend, the cornerstone of machine learning success remains in deployment – turning these sophisticated algorithms into practical, operational tools. In systematizing the knowledge about the newly developed FMOps infrastructure, we want to highlight that whether it's a traditional ML model or an advanced LLM, the deployment process shares many similarities. There are some additional considerations, of course, but a lot of what you heard might just be hype ;)
The earlier you deploy the model, the earlier you become aware of production issues. As a result, you can tackle them before you are set to deploy the final version of your model. It is estimated that about 80% of the ML models never make it to production! Today, we'll cut through the complexities, highlighting the key parallels and unique challenges in deploying both traditional and advanced models. This streamlined approach demystifies deployment, equipping you with best practices that you can follow even before training an ML model to make it easier and faster to deploy.
In today’s Token:
How to choose the right model?
Where can I store my embeddings?
Are feature stores any useful?
How can we get the best performance from a chosen model for our use case?
Now that I know how to choose a given model, how do I choose the infrastructure to deploy it?
I have deployed my model. Can I sit back and relax?
Conclusion
Bonus resources
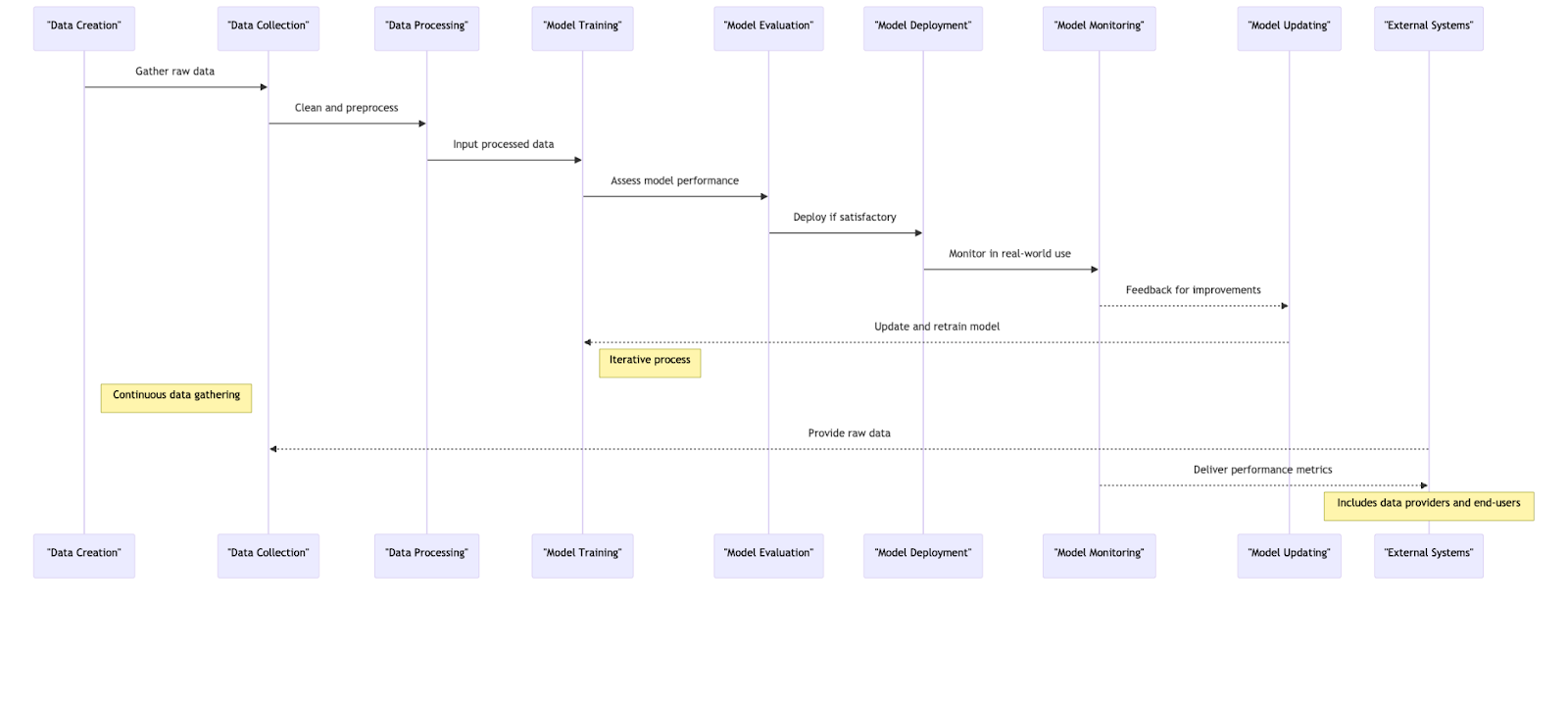
Let’s get started with how you can choose the right model.
How can I choose the model?
Well, the answer is, to use the simplest model that can get the job done. For instance, if you are working on a binary classification problem, start with logistic regression. There are two benefits to using the simplest model:
Simpler models are explainable
Simpler models can be trained quickly, and the team can focus on other phases of the ML lifecycle. This reduces the time to deployment.
For LLMs, this translates to using good enough models and prompt engineering instead of fine-tuning or training a custom LLM. For tasks like information extraction, where the required answer is present in the prompt itself, prompt engineering is very effective and less time-consuming than fine-tuning or training a custom model.
Choosing between open-source and closed-source foundation models involves weighing operational, financial, and strategic factors.
Closed-source models offer ease of use and robust support but come at a higher cost and with limitations in customization and potential provider dependency. They are ideal for those who prioritize reliability and simplicity over technical control.
Open-source models, while more affordable upfront, demand greater technical expertise and can incur hidden operational costs. They offer customization and innovation opportunities, but require significant investment in infrastructure and expertise management.
Where can I store my embeddings?
The rest is available to our Premium users only →
You will have access to the full archive, including the FMOps series and profiles of fascinating GenAI unicorns, plus much more.
Please give us feedback |
Thank you for reading, please feel free to share with your friends and colleagues. In the next couple of weeks, we are announcing our referral program 🤍
Previously in the FM/LLM series:
Token 1.1: From Task-Specific to Task-Centric ML: A Paradigm Shift
Token 1.5: From Chain-of-Thoughts to Skeleton-of-Thoughts, and everything in between
Token 1.6: Transformer and Diffusion-Based Foundation Models
Token 1.7: What Are Chain-of-Verification, Chain of Density, and Self-Refine?
Token 1.9: Open- vs Closed-Source AI Models: Which is the Better Choice for Your Business?
Token 1.10: Large vs Small in AI: The Language Model Size Dilemma
Token 1.13: Where to Get Data for Data-Hungry Foundation Models
Token 1.15: What are Hallucinations: a Critical Challenge or an Opportunity?
Join the conversation