- Turing Post
- Posts
- The History of Computer Vision on the Path to AGI
The History of Computer Vision on the Path to AGI
After the highly sought-after history of LLMs, we continue digging into machine learning annals and what is important to learn from them to thrive nowadays
Ksenia Se & Valeriia Kuka
April 10, 2024
Introduction
If we ever achieve Artificial General Intelligence (AGI), it will not happen solely thanks to Large Language Models (LLMs). While these models have made remarkable progress in natural language processing (NLP) and have given us the impression that machines can finally 'talk' to us, language by itself is simply not enough – and sometimes even unnecessary – for an intelligent creature. Language, in this sense, is not what directly contributes to intelligence; rather, it serves as a sign for us – self-acclaimed intelligent beings – that we are 'talking the same language' with the models.
If AGI ever becomes possible, language will once again play a more significant role in communication, allowing us to understand the models better. However, it is essential to consider how children and animals learn and develop intelligence. Children initially learn by sight, by ear, and by touch, relying on their senses to understand the world around them. Similarly, animals can understand us through speech recognition and/or visual perception without relying on text, emphasizing the importance of non-linguistic cues in intelligence.
While not dismissing the importance of advancements in language models and acknowledging the significant progress in NLP (we even have an amazing series about The History of LLMs), as exemplified by models like GPT (Generative Pre-trained Transformer), it is crucial to highlight the importance of computer vision (CV) in understanding the physical world. In this adventure series about CV, you will learn about all the struggles the researchers went through from the late 50s up to nowadays; the main discoveries and major roadblocks for real-life implementation, dead ends, and breakthroughs; and how much computer vision has changed our lives. But first, let's explore what computer vision entails.
What is computer vision?
If you like what we do, become our Premium subscriber →
In humans and other animals, vision involves the detection of light patterns from the environment and their interpretation as images. This complex process relies on the integration of sensory inputs by the eyes and their subsequent processing by the brain, interconnected by the nervous system. A resulting intricate network enables humans to filter and prioritize stimuli from a constant influx of sensory information, transforming light patterns into coherent, meaningful perceptions.
We will see in the future episodes, that researchers tried very different approaches to teach machines to see, perceive, and interpret images. Don't be fooled (or upset) by the anthropomorphizing wording. Despite the field's advancements, current computer vision techniques remain fundamentally different from human vision. They are based on sophisticated algorithms and models that approximate visual processing, rather than duplicating the biological complexity of human sight.
It's an irony, but even with such advancements in language processing, we still can't process with the right language to avoid anthropomorphizing machines.
How does it work?
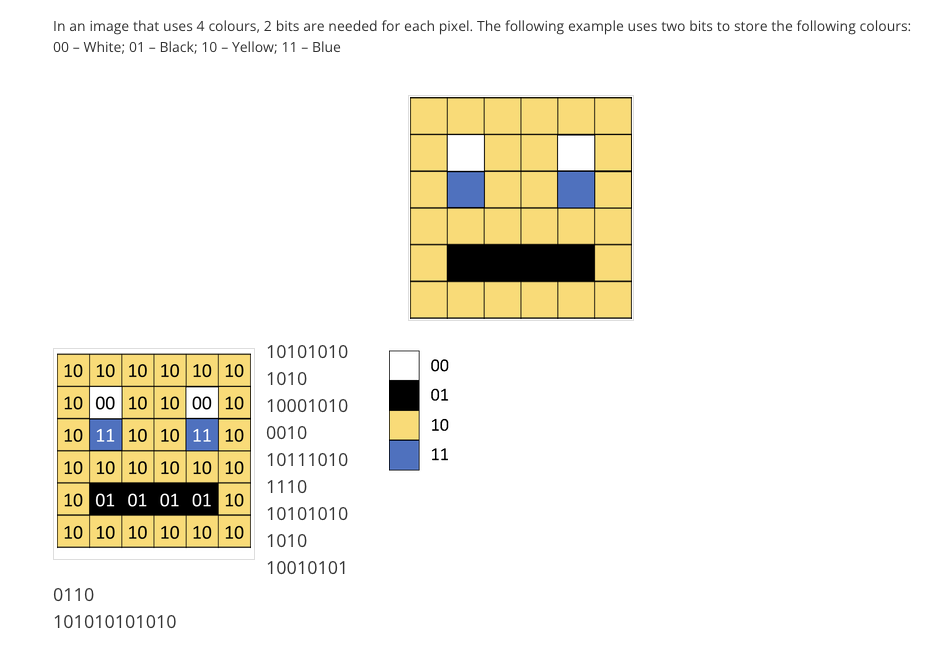
Now, let's dive into the technical aspects of computer vision. Scientists have long been fascinated with the idea of translating the vision ability of humans into something computer-readable. From the outset, researchers faced the critical task of determining how to describe and identify objects within an image to a computer, including deciding which features were most essential for recognition. It may seem to be very straightforward for people as they're wired for that but for machines... For computers, an image is just a collection of pixels, a binary code that is stored in computer memory.
“A major source of difficulty in many real-world artificial intelligence applications is that many of the factors of variation influence every single piece of data we are able to observe. The individual pixels in an image of a red car might be very close to black at night. The shape of the car’s silhouette depends on the viewing angle. Most applications require us to disentangle the factors of variation and discard the ones that we do not care about.”
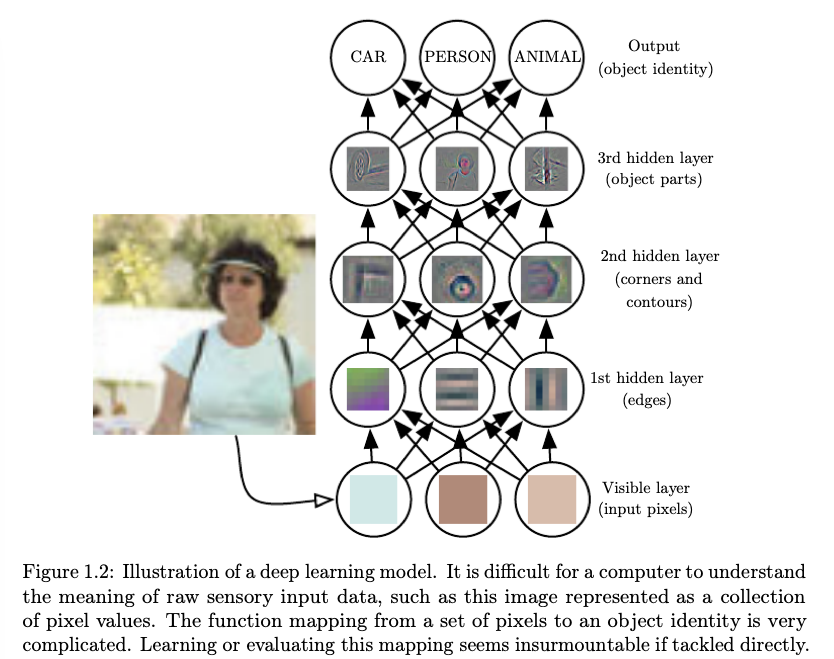
Teaching a machine to 'see' is complex. It's not just about the capture of images, but the interpretation of what those images mean. Computer vision breaks this down into several key steps:
Object Recognition: At its most basic level, CV systems learn to identify what's in an image; cars, people, animals, furniture, and so on. This is a building block for further understanding.
Semantic Segmentation: Taking it further, CV can learn to label every single pixel in an image, classifying them as belonging to certain object categories. Imagine an image colored not with light and shadow, but with labels – this is how a sophisticated CV system might 'see'.
Visual Relationships: Real intelligence understands not just objects, but how they relate. Is a person standing beside a car, or about to get into it? CV algorithms that grasp these spatial and contextual relationships bring an AI closer to comprehensive scene understanding.
The Process of ‘Seeing’
This process can be broadly categorized into several steps, mirroring aspects of human visual processing:
Image Acquisition: The journey starts with capturing an image or video, and converting the visual information into a digital format that a computer can process.
Preprocessing: Here, the digital image is refined, enhancing its quality through techniques like noise reduction and contrast adjustment to ensure accurate analysis.
Feature Extraction: The essence of computer vision lies in identifying and isolating specific features within an image. These features could be edges, textures, colors, or shapes that are critical for the subsequent steps of object detection and recognition.
Detection/Segmentation: This phase involves differentiating objects from the background (segmentation) or identifying particular objects within the image (detection). It's a pivotal step in making sense of the visual data by pinpointing areas of interest.
Classification/Recognition: At this stage, the identified objects are classified or recognized. This means assigning a label to an object based on its features, essentially allowing the system to 'understand' what it is seeing.
Post-processing: The final touch includes refining the output, considering the broader context, or integrating additional data sources to enhance the accuracy and reliability of the interpretation.
What made computer vision possible?
Computer vision mirrors human visual processes but operates under the constraints of technological infancy. While human vision benefits from a lifetime of contextual learning – distinguishing objects, gauging distances, and recognizing movement – computer vision seeks to replicate these abilities through data, algorithms, and hardware. Despite starting from scratch, these systems can quickly outpace human capability by processing and analyzing thousands of items or situations per minute, identifying nuances and defects that might escape the human eye.
At the heart of computer vision's functionality is an insatiable appetite for data. It thrives on vast datasets, processing and reprocessing this information to distinguish between different visual elements and recognize specific objects or features. This learning process is powered by two pivotal technologies:
Deep Learning: A subset of machine learning, deep learning uses algorithmic models that enable systems to self-educate on the context and content of visual data. By feeding these models a continuous stream of data, the computer learns to differentiate and identify images through self-guided algorithms.
Convolutional Neural Network (CNN): CNNs are crucial for breaking down images into manageable pieces – pixels tagged with labels. These labels assist in performing mathematical operations (convolutions) that iteratively predict the content of the images. This process, mirroring the gradual refinement of human sight from recognizing basic shapes to detailed objects, allows the computer to "see" in a manner akin to human vision.
The challenge of imparting basic human abilities, such as sensory and perceptual skills innate to even a one-year-old, to a computer, was crystallized by Hans Moravec, Rodney Brooks, and Marvin Minsky through a concept known as Moravec's Paradox. This principle posits that replicating these seemingly simple skills demands far more computational resources than solving problems humans find complex.
One reason for that is that we barely know ourselves.
"In general, we're least aware of what our minds do best."
The crux of the issue lies in reverse engineering a process that, for us, is as natural as breathing yet as enigmatic as the universe itself. Articulating a profoundly complex problem for algorithmic treatment becomes much simpler when the underlying algorithm is known – consider, for instance, devising an optimal strategy using game theory. While such an algorithm might be comprehensible to only a select few due to its complexity, it paradoxically requires significantly fewer computational resources for a computer to execute.
We will guide you through all the ups and downs of the research and development process from the late 1950s in this historical series about CV.
The areas that can not exist without computer vision

This accelerated learning and operational capability is what makes computer vision invaluable across various industries – from energy and utilities to automotive manufacturing. And that effects →
Computer vision market
To know about computer vision is also important because the market for it is … large. It is experiencing substantial growth, with projections varying significantly between different sources:
Statista: With the size projected to reach $26.26 bn in 2024, expected to grow at a CAGR of 11.69% until 2030 to reach $50.97 bn.

Grand View Research: With a size of $14.10 bn in 2022, growing at a CAGR of 19.6% until 2030 to reach $58.29 bn.
Allied Market Research: with the size valued at $15 bn in 2022, growing at a CAGR of 18.7% until 2032 to reach $82.1 bn by 2032.
Conclusion or Why should you follow this series?
In this series, we focus on the role of computer vision in the development of AGI because a comprehensive understanding of the world requires more than just language processing. We believe that looking back at history helps us understand what worked, and what didn't, and can contribute to the cross-pollination of ideas for our readers. We want to answer these questions: What were the challenges of the past and how they were solved? Could it help researchers solve the current challenges? What are some unexpected intersections of ideas that could lead to innovative solutions?
In the upcoming articles, we will dive deeper into the early inspirations and theoretical foundations laid down by pioneers in the field of computer vision, explore key milestones and breakthroughs, discuss recent advancements and their applications, and examine the challenges and future directions of this rapidly evolving field. By understanding the past and present of computer vision, we can better appreciate its significance in the pursuit of AGI and anticipate the exciting possibilities that lie ahead.
Next episode: The Pioneering Era: 1950s to 1970s - How did it all start? Or The Dawn of Computer Vision: From Concept to Early Models
How did you like it? |
Thank you for reading, please feel free to share with your friends and colleagues and receive one month of Premium subscription for free 🤍
Join the conversation